

The functioning/operations of large corporations are tightly coupled with the use of spreadsheets/Excel files; from the list of applicants organized via Google sheets and the task separation of individual employees to the financial and budget projections of the entire company, businesses rely on tabular forms much more than imagined. However, while we have settled down to the unified Excel automation for our data, converting information from various medium to such formats may involve intensive labour hours that may otherwise be utilised for other tasks.
Also read: How to convert Word to Excel?

The advances in computer vision and text understanding techniques have ultimately led to the rethinking of data extraction processes – how can we leverage deep learning techniques into helping us understand, extract, and organize data to mathematically computable excel format?
This article discusses the major progress made in the past decade on the automated PDF data extracting approaches and conversion to CSV files, with a brief highlight upon the deep learning methodologies, tutorials, and existing solutions in the market for accomplishing this task.
What Kind of Data to Extract?
Before diving into the core extraction process, one should first understand the “kind” of data we are aiming to obtain. Numerous data structures exist in PDFs, of which tabular and key-value-pairs (KVPs) are the most common and obvious.
Tabular Formats
Data in tabular formats may seem trivial for extraction, but it is actually a challenging task due to the inherent storing format of PDFs.
In many PDFs, texts and tables are presented as pixels rather than machine-encoded words. In other words, they are just black and white, unstructured pixels like any other images. Therefore, the extraction of tabular data often requires table and text detections prior to actual word understanding.
Even parsing Excel or CSV data can get tricky when dealing with large data sets.
Key-Value Pairs
Sometimes categorical information may not be presented explicitly with tabular lines, but instead as KVPs, two linked data items as a key and a value, where the key is a unique identifier for the value. Some examples of this include the data presented on passports. While these data can consequently be converted into tables into excel files, they were originally presented as KVPs instead of visible tables. Extraction of such data is therefore much more difficult and could require additional state-of-the-art deep learning techniques.
Techniques Behind Extraction and Table Conversion

While the conversion of data structures to CSV files that could be directly imported into Excel files is straightforward, data extraction can be inherently difficult due to the aforementioned reasons. This section briefly describes the concept of artificial intelligence and machine learning, particularly deep learning in computer vision for optical character recognition (OCR).
Artificial Intelligence and Machine Learning
People often associate the two terms interchangeably, but they actually withhold a subtle difference in meaning. Artificial intelligence is the broad term in describing any machine-aided software that could be in help to perform based on decisions, whether the decision was performed via rule-based or learnt settings.
Machine learning, on the other hand, specifically describes the approach of utilizing inputs and designated outcomes to ‘learn’ the intermediate system for future decision making/predictions. Such a setting may sound odd at first, as traditional computer software aims to design the intermediate system so that the input, through the system, can produce accurate outcomes. However, machine learning has been proven successful when the intermediate system is too difficult to design due to the complex tasks we are performing. Example applications include difficult image-related tasks such as image classification, object detection, and of course, character recognition.
Deep Learning in Computer Vision
Deep learning is an even more specific branch of machine learning, where we design multi-perceptron layers, or neural networks, for approximating the intermediate system.
Neural networks are architectures inspired by the biological neural network, which comprise multiple layers of neurons that act as activation functions when an input is fed into the network. Based on the ground truth prediction, the neuron weights are updated accordingly so that only the ‘correct’ activations are performed, making proper decisions. We often refer to this process as back propagation.
This architecture was proposed in the early 1970s, but the development suffered due to the high computation required that were only resolved recently with the rise in GPU computational power.

With the strong modelling results of deep learning, almost all computer vision tasks (i.e., the task to allow computers to understand images) are aided fully or at least partially by deep learning. One particular type of neural network used for computer vision tasks is the convolutional neural networks (CNNs), which introduces traditional convolutional kernels that slide through images to extract features. Coupled with traditional network layers, current research has achieved state-of-the-art results in classifying and detecting objects within an image, not to mention its stunning accuracy in OCR.
OCR
Traditionally, the process of extracting letters from a document and converting them to machine-encoded texts is done by rule-based scanning. This has quickly given way to the aforementioned deep learning methods that could adapt to various fonts, styles, and sometimes even handwritten characters.
In addition, with the help of designated network architectures such as long-short term memories, classification of characters can become much more accurate with the understanding of context from letters prior or after the character (e.g., after “d” and “o”, “g” is a much more probable character than “z”).
Read About: Best PDF to Excel Converters
Pipeline
With a brief understanding of the deep learning technology, we then introduce the pipeline of converting table data from PDFs to Excel files:
- Detect all the words on the PDF via OCR
- Detecting all the bounding boxes on the PDF
- Based on the explicit bounding boxes and PDFs, convert data into data structures such as lists and dictionaries
- Export lists and dictionaries into CSV files for Excel processing.
Tutorials
The tutorial consists of two components: the OCR conversion and the CSV export. In simple words, the process of converting tables from PDFs into excels and tables requires first good extraction of the words and tables from PDFs, followed by the exporting step.
The tutorial will be mostly in Python, with the help of Google API and some in-built libraries Python offers for PDF conversion and exporting
Tutorial Part 1 - OCR Conversion
To first perform OCR, one may need to convert PDF to image formats. This can be achieved via the pdf2image library by installing the following
pip install pdf2imageThe two ways to convert from path and from bytes are listed as the following.
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
images = convert_from_path('example.pdf')
images = convert_from_bytes(open('example.pdf','rb').read())For more information on the code, you can refer to the official documentation.
Afterward, you may then refer to the Google Vision API for OCR retrieval. Big corporations like Google and Amazon are benefitted from the massive crowdsourcing owing to their vast customer base. Therefore, instead of training your personal OCR, using their services may have much higher accuracies.
The entire Google Vision API is simple to setup, one may refer to its official guidance for the detailed setup procedure.
The following is the code for OCR Retrieval:
def detect_document(path):
"""Detects document features in an image."""
from google.cloud import vision
import io
client = vision.ImageAnnotatorClient()
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
for page in response.full_text_annotation.pages:
for block in page.blocks:
print('\nBlock confidence: {}\n'.format(block.confidence))
for paragraph in block.paragraphs:
print('Paragraph confidence: {}'.format(
paragraph.confidence))
for word in paragraph.words:
word_text = ''.join([
symbol.text for symbol in word.symbols
])
print('Word text: {} (confidence: {})'.format(
word_text, word.confidence))
for symbol in word.symbols:
print('\tSymbol: {} (confidence: {})'.format(
symbol.text, symbol.confidence))
if response.error.message:
raise Exception(
'{}\nFor more info on error messages, check: '
'https://cloud.google.com/apis/design/errors'.format(
response.error.message))Note that document_text_detection is one of the functions they offered that specialises in very condensed texts that appears mostly in PDFs. If your PDF has words somewhat more scarce, it may be better to use their other text detection function which focuses more on in-the-wild images. More codes regarding the usage of Google API can be retrieved here; you may also refer to codes in other languages (e.g., Java) if you are more familiar with them.
There are also other OCR services/APIs from Amazon and Microsoft, and you can always use the PyTesseract library to train on your model for specific purposes.
Tutorial Part 2 - CSV Export
CSV Export from Python is the final and perhaps simpler part of the entire process. In Python, when your data is stored as lists perhaps as the following:
# field names
fields = ['FirstName', 'Surname', 'Year', 'CGPA']
# data rows
rows = [ ['Nikhil', 'John', '2', '9.0'],
['Sam', 'Cheng', '2', '9.1'],
['Adi', 'Travolta', '2', '9.3'],
['Lorenzo', 'Thomas', '1', '9.5'],
['Stuart', 'Ali', '3', '7.8'],
['Saz', 'TY', '2', '9.1']] You may simply put them into CSVs via a CSV writer like this:
with open('people.csv', 'w') as f:
write = csv.writer(f)
write.writerow(fields)
write.writerows(rows)If you run the code, then you will have a people.csv file within the directory, which you can directly open it with Excel for further processing.
You may also use f = open.... followed by f.close() if there are a lot of processing in between the writing of rows.
Solutions in the Market
More and more companies now hope to transform their data conversion processes into automated pipelines. Therefore, many firms (e.g., Google, Amazon) now offer APIs to perform such tasks. Here we list some popular solutions that offer OCR and table detection and their pros and cons:
*Side Note: There are multiple OCR services that are targeted towards tasks such as images-in-the wild. We skipped those services as we are currently focusing on PDF document reading only.
- Google API -- Google’s unbeatable results in data extraction are due to the massive crowdsourcing of datasets from their search engine. They offer free trials for personal usage but price soon builds up when the calls rise to business scale.
- Deep Reader -- Deep Reader is a research work published in ACCV Conference in 2019. It utilizes multiple state-of-the-art network architectures to perform tasks such as document matching, text retrieval, and denoising images. There are additional features such as tables and key-value-pair extractions that allow data to be retrieved and saved in an organized manner.
- Nanonets – With a highly skillful deep learning team, Nanonets PDF OCR is completely template and rule independent. Therefore, not only can Nanonets work on specific types of PDFs, it could also be applied onto any document type for text retrieval. Tasks such as extracting tables are also built-in, allowing flexible yet highly accurate retrieval from all types of documents.
Nanonets -- Simple Yet Elegant
One of the highlights of Nanonets is the simplicity the service brings. One can opt for these services without any programming background and easily extract tabular data with the cutting edge technology. The following is a brief outline of how easy it is to access Nanonets for converting tables from PDFs to Excel:
Step 1
Go to nanonets.com and register/log in.
Step 2
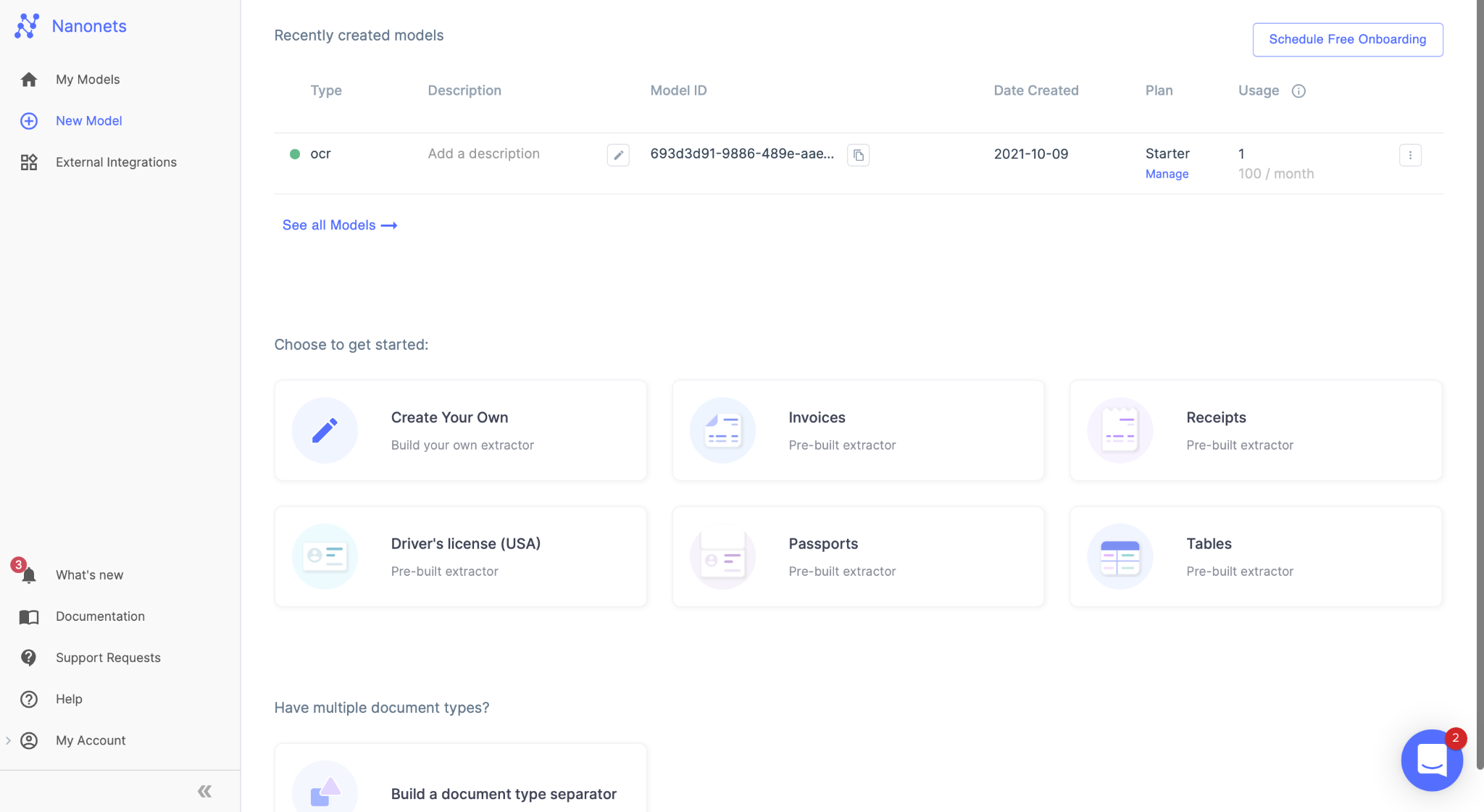
After registration, go to the “Choose to get started” area, where all the pre-built extractors are made and click on the “Tables” tab for the extractor designed for extracting tabular data.
Step 3
After a few seconds, the extract data page will pop up saying it is ready. Upload the file for extraction.

Step 4
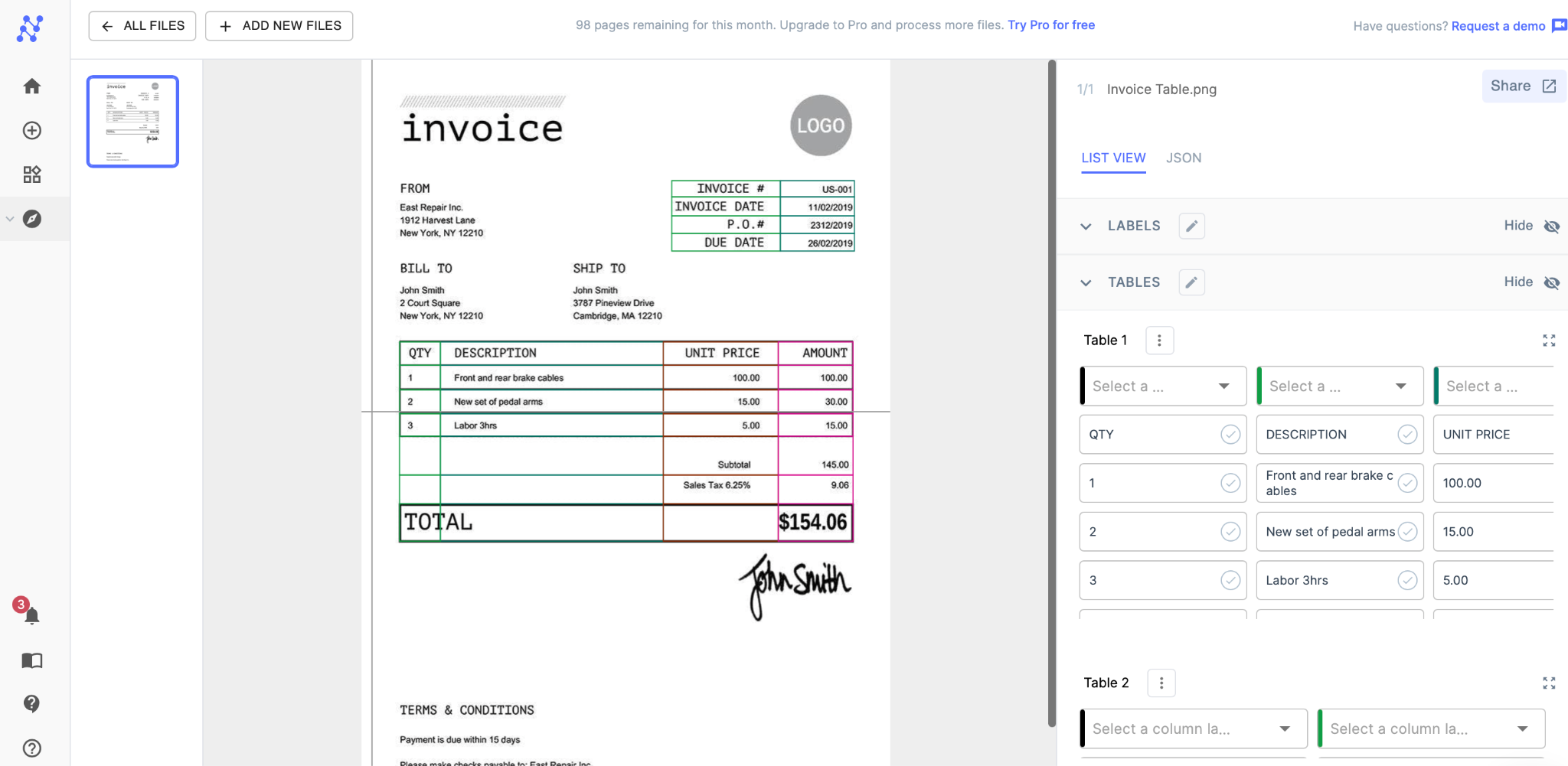
After processing, Nanonets can properly extract all the tabular information accurately, even skipping the empty spaces!
Conclusion
This article provides some insights into the process of extracting and converting tables from PDFs and further exporting them to CSV files to open through Excel. The two tutorials hopefully serve as an entry point to how much convenience such an automated process can bring.