

This blog post is a starting point for anyone looking to perform OCR on PDF files and images. We start with a Python code tutorial that takes you through the process of performing OCR on PDF files and images and discusses more specific OCR functionalities and their implementation after the introductory section. We end by introducing a set of free online OCR tools and links.
Did you know that there are over 3 trillion PDF documents worldwide? One of the reasons for their popularity is their ability to provide a consistent user experience across multiple platforms.
As a result, more and more people and organizations are turning to AI-powered solutions to extract text and tabular information from PDFs. If you are one of them, we recommend checking out our specialized blogs that provide solutions for various use cases, including data extraction from PDFs.
- Reading Invoices and extracting attributes such as invoice amount, buyer, seller, date of invoice, etc. for accounts payable automation.
- Reading Passports, Driving Licenses, Identity Cards and extracting attributes such as document owner, authority, date of issue, place of issue etc.
- Document Separation and Sorting based on nature and purpose of document from a set of documents of various types.
- Storing text from PDFs contained in a digitally recognized and searchable form for subsequent searching and lookups.
OCR uses AI to convert printed or handwritten text into machine-readable text. There are various open-source and closed-source OCR engines available. However, the output generated by OCR may need further processing to extract relevant attributes in a structured format.

Convert PDFs to JSON in seconds with AI!
▼
Convert PDFs to JSON in seconds with AI!
Python Functions for Image and PDF OCR: Optimize Your Text Recognition
Our team has released a free library to contribute towards the cause of quality free OCR tools being made available for educational and research purposes.
Salient Features of the library:
- Recognizes PDF and image formats, no preprocessing required.
- Retains spatial formatting of the original document accurately.
- Can detect and extract tables in Excel / CSV format from PDF/image.
- Create searchable PDFs from scanned PDFs on the fly.
I am sharing a small code snippet below to get you started.
You can install the package using pip.
pip install ocr-nanonets-wrapper
To get your first prediction, run the code snippet below. You must add your API key to the third line to authenticate yourself.
This software is perpetually free. You can get your free API key (with unlimited requests allowed) by signing up at https://app.nanonets.com/#/keys.
from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
We are all set now to make the first prediction. You can give inputs by specifying a local file or a URL. Note that the file/URL can be both a PDF or image file and have a .pdf, .jpg, or .png file format.
We will use the below image to make the first prediction.

prediction_json = model.convert_to_prediction('pred.png')

We have stored the output of the OCR engine in prediction, which is a json object. This object contains predicted words and their spatial positioning in the document. This object helps you store the JSON and create your own methods to interpret and format the OCR output.
However, you can directly get OCR outputs in desired formats using other functions in the package.
1. Extract Text from the File as a String
After authenticating, you can just run the code snippet below to extract all text from your input file and store it in a string.
from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
string = model.convert_to_string('INPUT_FILE',formatting='lines and spaces')
print(string)
# formatting can be => none / lines / lines and spaces / pages
# output examples of these different formatting options shown below
You can change the formatting option. The default setting is 'lines and spaces', which extracts all text from your file and converts it into a string while retaining all spaces and newlines, thus maintaining the spatial structure of the original file.
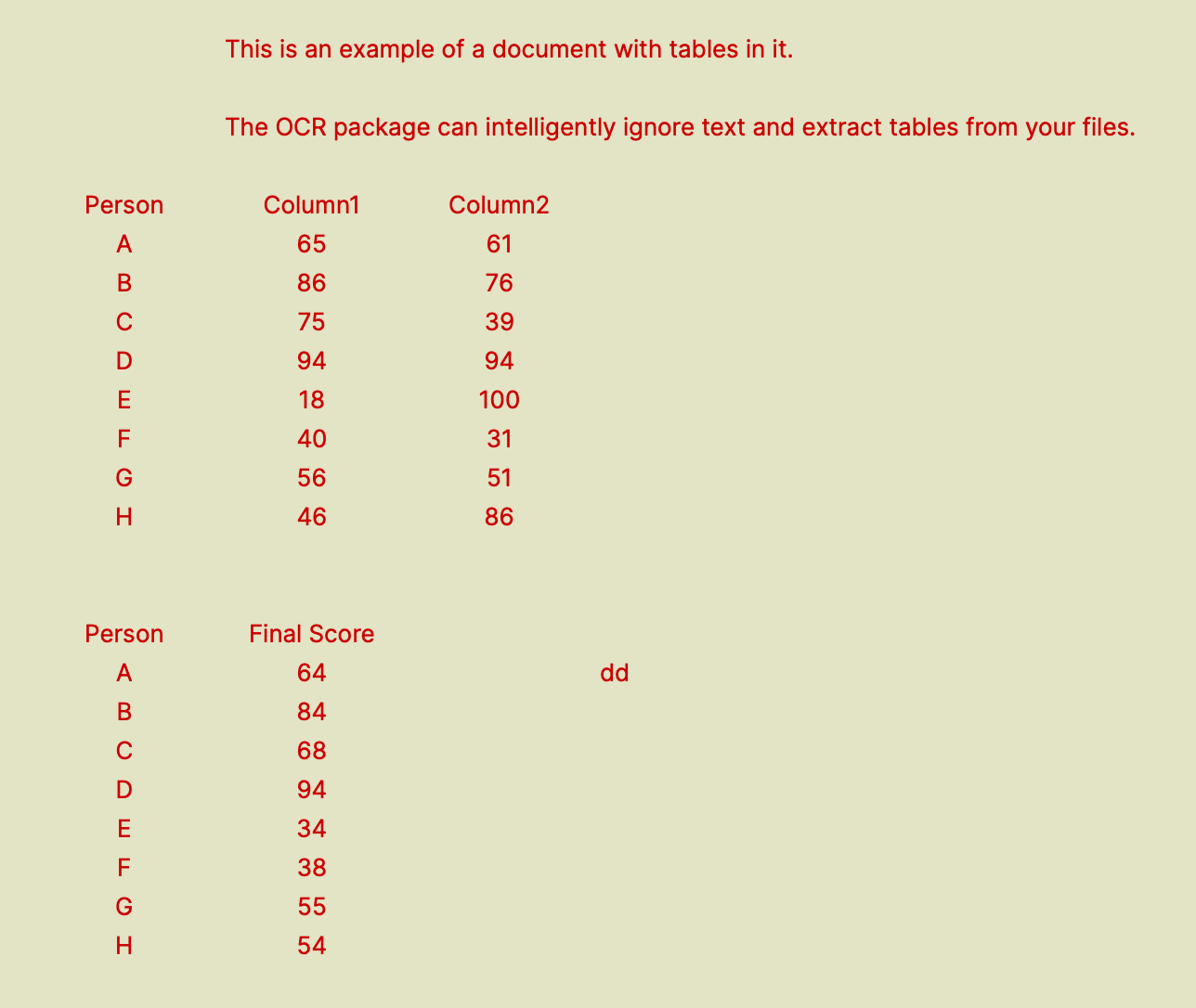
Let us see how the formatting parameter works. We will read the below image using different formatting modes.

You can see how formatting mode changes the output string in below screenshots.



As you can see, the formatting = 'lines and spaces' mode works really well if you want to read your file and print it in the orientation matching your original file. Let me share another example here. Consider the below file where we run the convert_to_string method with formatting = 'lines and spaces' mode.
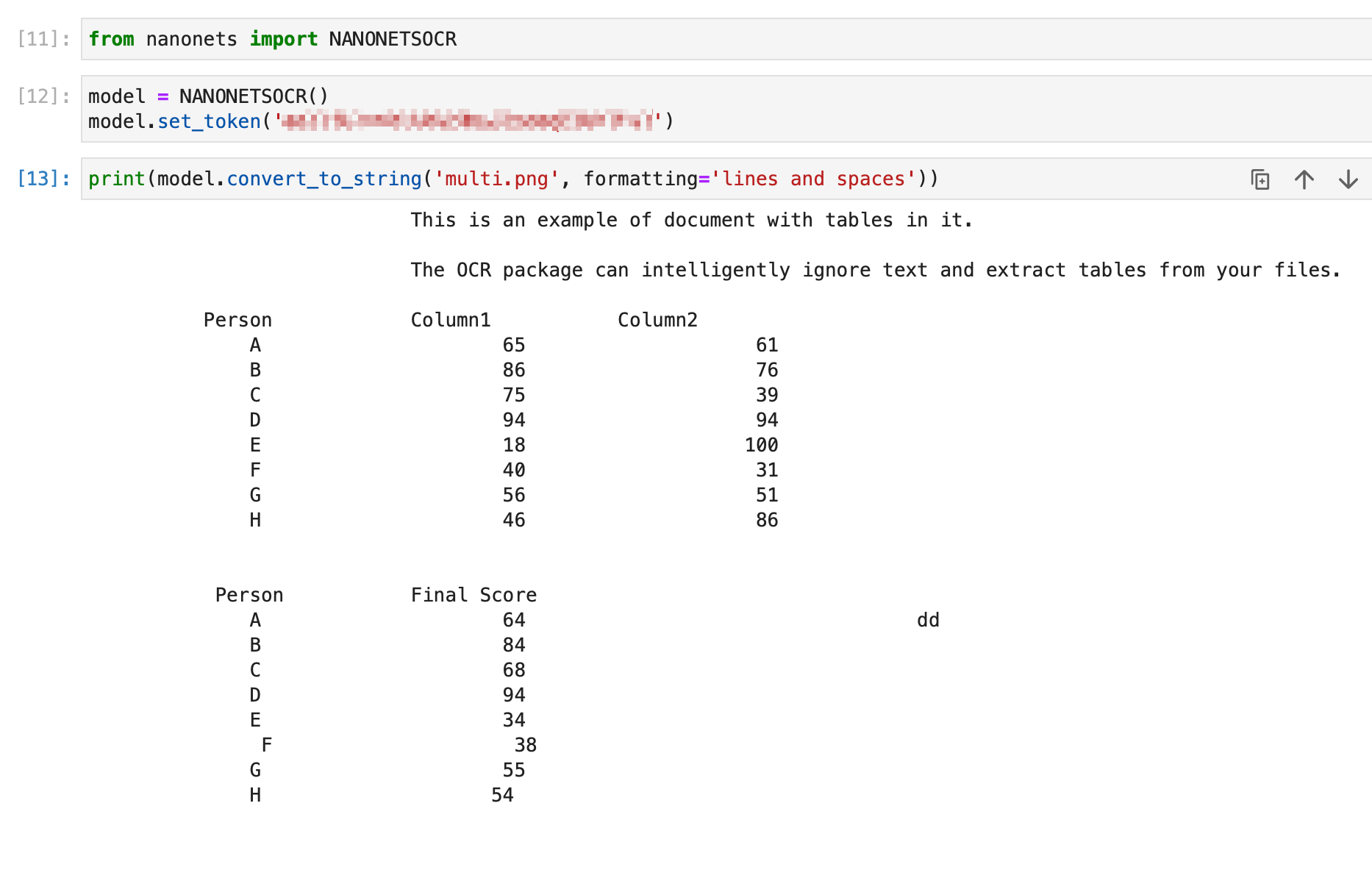
2. Convert PDF / Image to Text File
This method of converting PDF to TXT works similarly to the convert_to_string method shown above. The difference is that while convert_to_string returns a string, this method creates a .txt file directly with the output of the convert_to_string method.
The formatting parameter works the same way as it does for the convert_to_string parameter. You can optionally specify the file name for the output .txt file.
from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
model.convert_to_txt('INPUT_FILEPATH', output_file_name = 'OUTPUT.txt')
3. Get Bounding Box Information
The package can extract data from your files and store bounding box information. The output is a list of dictionaries containing each word and its spatial position in the file.

from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
boxes = model.convert_to_boxes('test.png')

4. Extract Tables from File (Convert to CSV)
This method allows you to extract all tables from your file. You can store the information in a JSON object or directly get the results in a .CSV file.
As an example, we will extract tables from the below image.
Note: If extracting flat fields, tables and line items from PDFs and images is your use case, I will strongly advice you to create your own table extraction model by signing up on [app.nanonets.com] and using our advanced API. This will improve functionalities, accuracy and response times significantly. Once you have created your account and model, you can use API documentation present here to extract flat fields, tables and line items from any PDF or image.
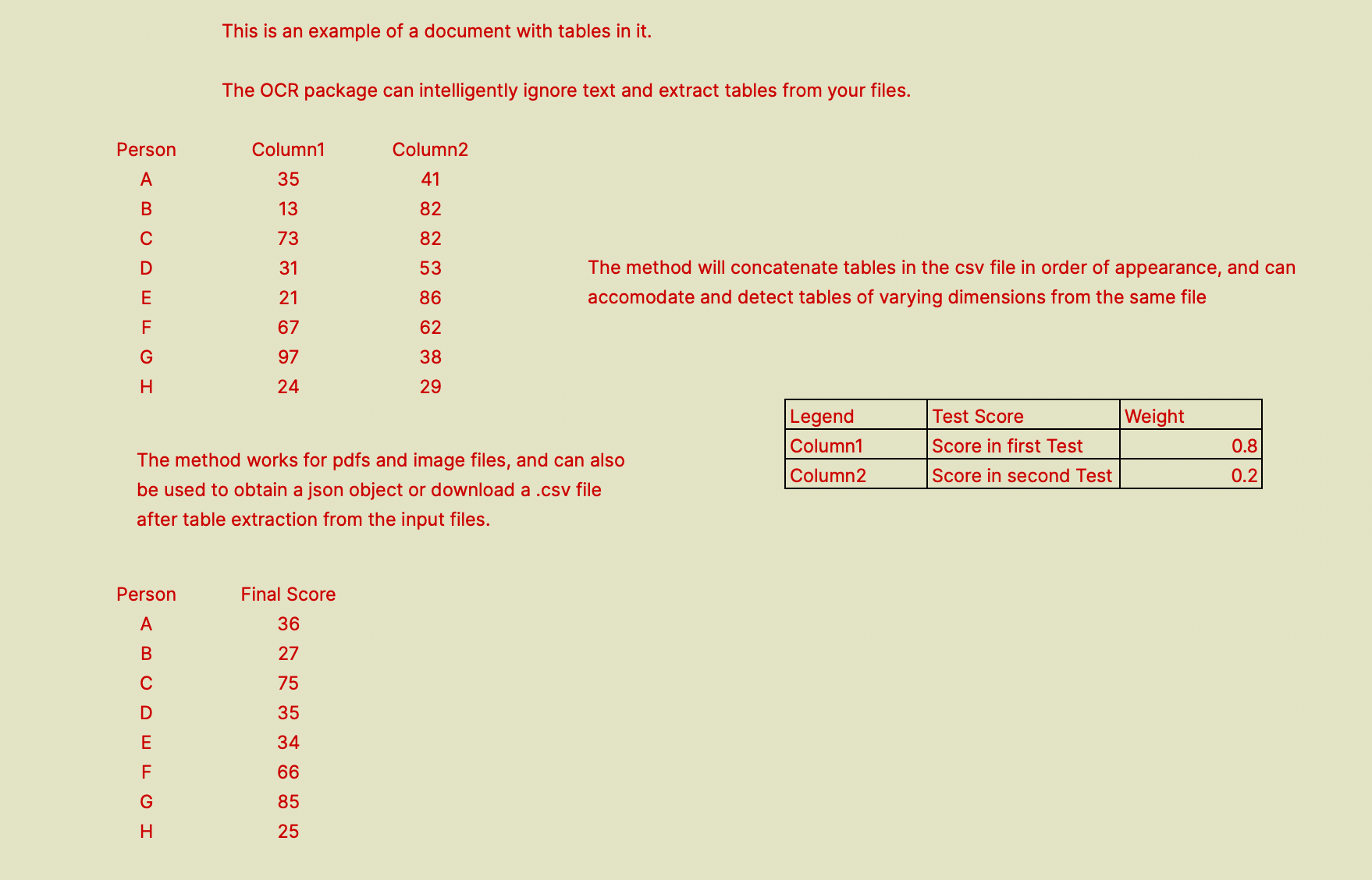
You can run the code snippet below to get a . CSV file with all tables extracted from the input file. I have run it on the above sample image and attached the output CSV.
from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
model.convert_to_csv('tables.png',output_file_name='OUTPUTFILE.csv')
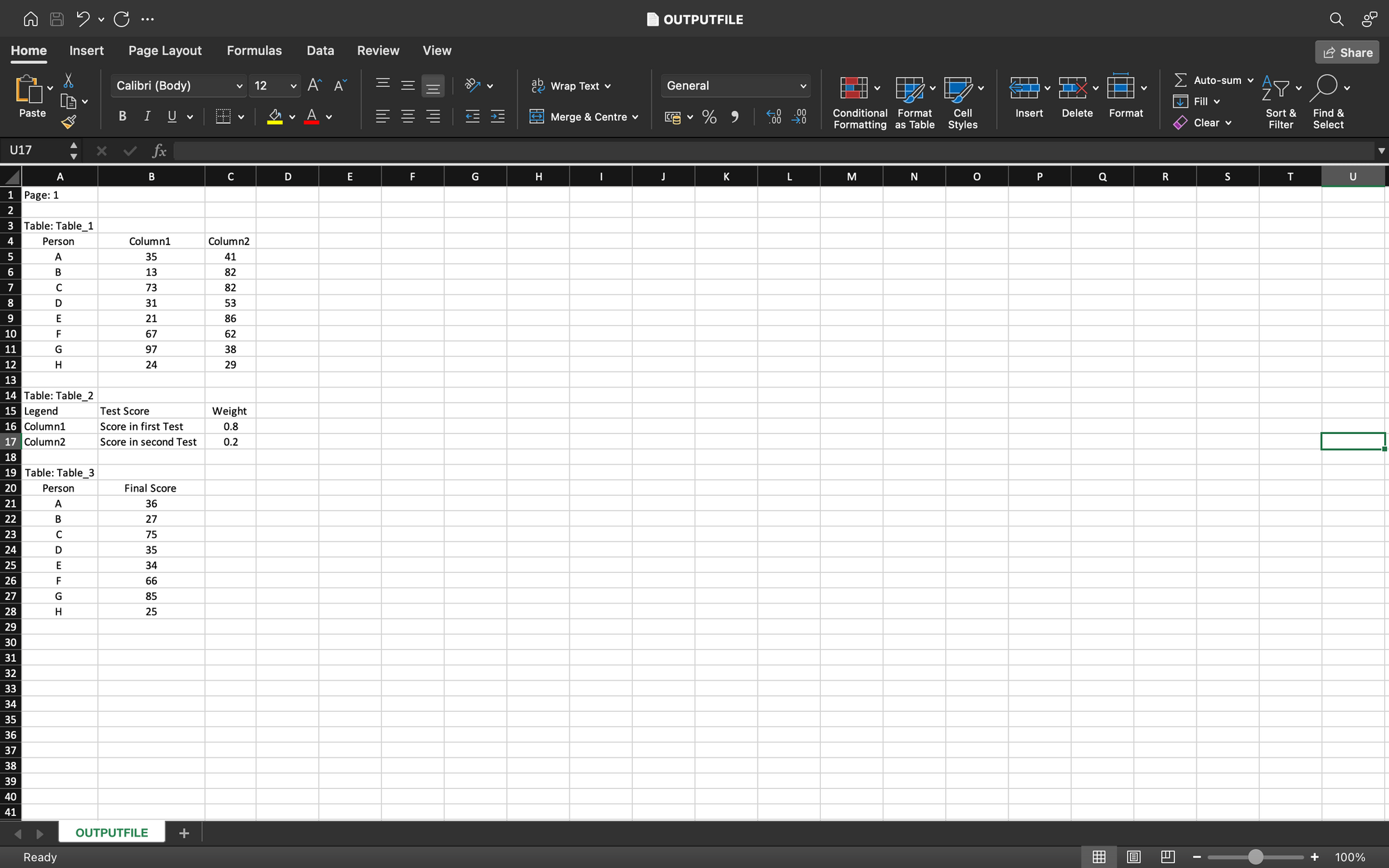
Instead, if you want a JSON object containing all the tables, you can run the snippet below on the same file.
from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
tables_json = model.convert_to_tables('tables.png')

Note :
- This function (
convert_to_csv()andconvert_to_tables()) is a trial offering 1000 pages of use. - To use this at scale, please create your own model at app.nanonets.com --> New Model --> Tables.
5. Convert to Searchable PDF
You can directly convert your PDF or image file to a searchable PDF using the below code snippet. This will create a .pdf file as output. You will be able to search and detect all the text present in this output .pdf file.
from nanonets import NANONETSOCR
model = NANONETSOCR()
model.set_token('REPLACE_API_KEY')
model.convert_to_searchable_pdf('inv.png',output_file_name='output.pdf')
This code snippet creates a searchable pdf with file name output.pdf, which has machine recognizable text. You can search for text / numbers and lookup using the search functionality on your PDF viewer or document management system.
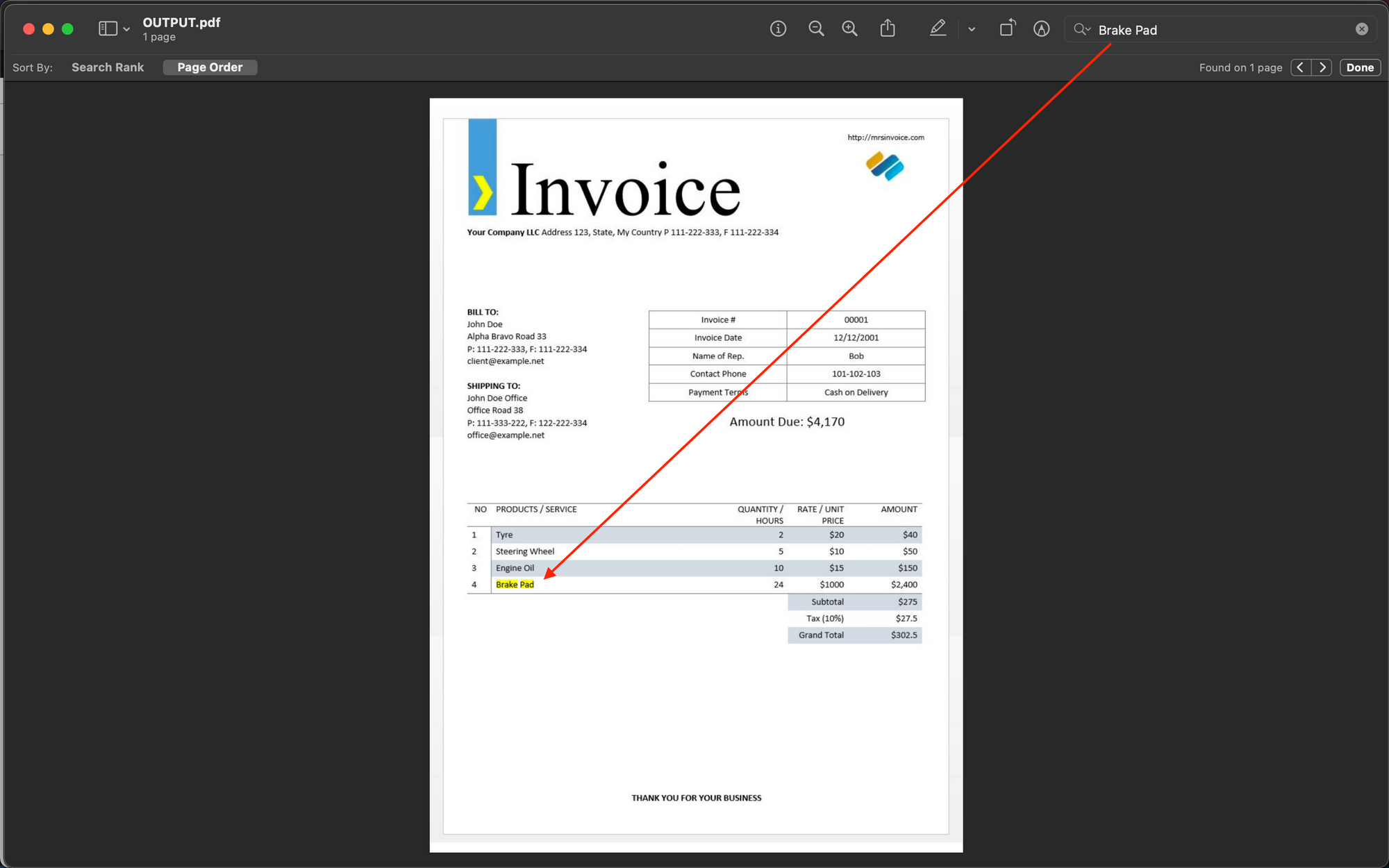
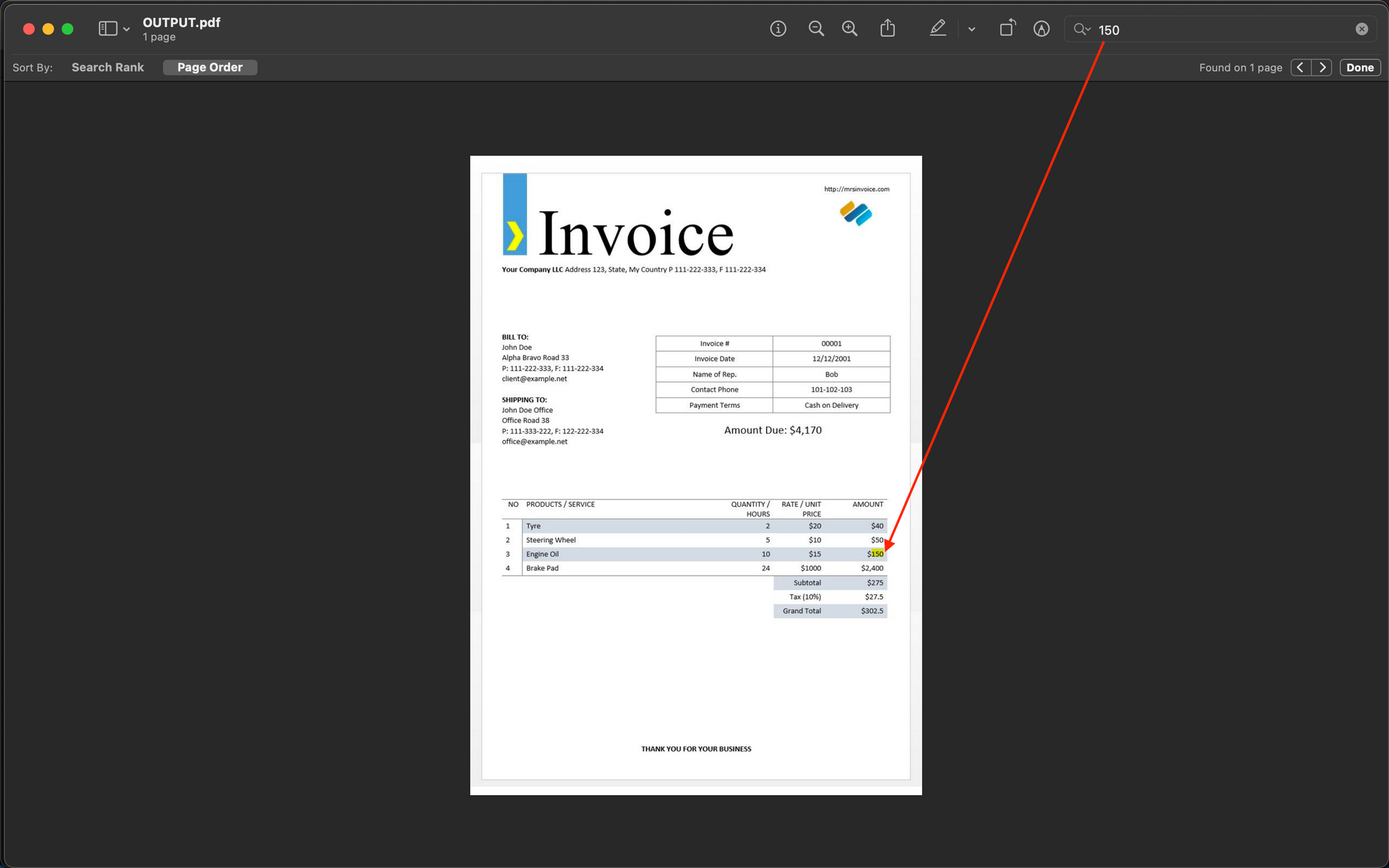
Python Code - Read your first PDF File Using Pytesseract
Tesseract is another popular OCR engine, and Pytesseract is a Python wrapper built around it. Let us take an example of the PDF invoice shown below and extract text from it.
The first step is to install all prerequisites in your system.
Tesseract
Installing the Tesseract OCR Engine is the first step here.
- Windows - installation is easy with the precompiled binaries found here. Do not forget to edit the “path” environment variable and add the Tesseract path.
- Linux - can be installed with few commands.
- Mac - The easiest way to install on Mac is using homebrew. Follow the steps here.
After the installation, verify that everything is working by typing the command in the terminal or cmd:
$ tesseract --version
And you will see the output similar to:
tesseract 5.1.0
leptonica-1.82.0
libgif 5.2.1 : libjpeg 9e : libpng 1.6.37 : libtiff 4.4.0 : zlib 1.2.11 : libwebp 1.2.2 : libopenjp2 2.5.0
Found NEON
Found libarchive 3.6.1 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3 libzstd/1.5.2
Found libcurl/7.77.0 SecureTransport (LibreSSL/2.8.3) zlib/1.2.11 nghttp2/1.42.0Pytesseract
Python wrapper for Tesseract. You can install this using pip.
$ pip install pytesseract
pdf2image
Tesseract takes image formats as input, meaning we will be required to convert our PDF files to images before processing using OCR. This library will help us achieve this. You can install this using pip.
$ pip install pdf2image
OCR using Pytesseract
Now, we are good to go. Reading text from PDFs is now possible in a few lines of Python code.
import pdf2image
from PIL import Image
import pytesseract
image = pdf2image.convert_from_path('invoice-sample.pdf')
for pagenumber, page in enumerate(image):
detected_text = pytesseract.image_to_string(page)
print(detected_text)
Running the above Python code snippet on the above pdf invoice example ('invoice-sample.pdf'), we obtain the output below from the OCR engine.
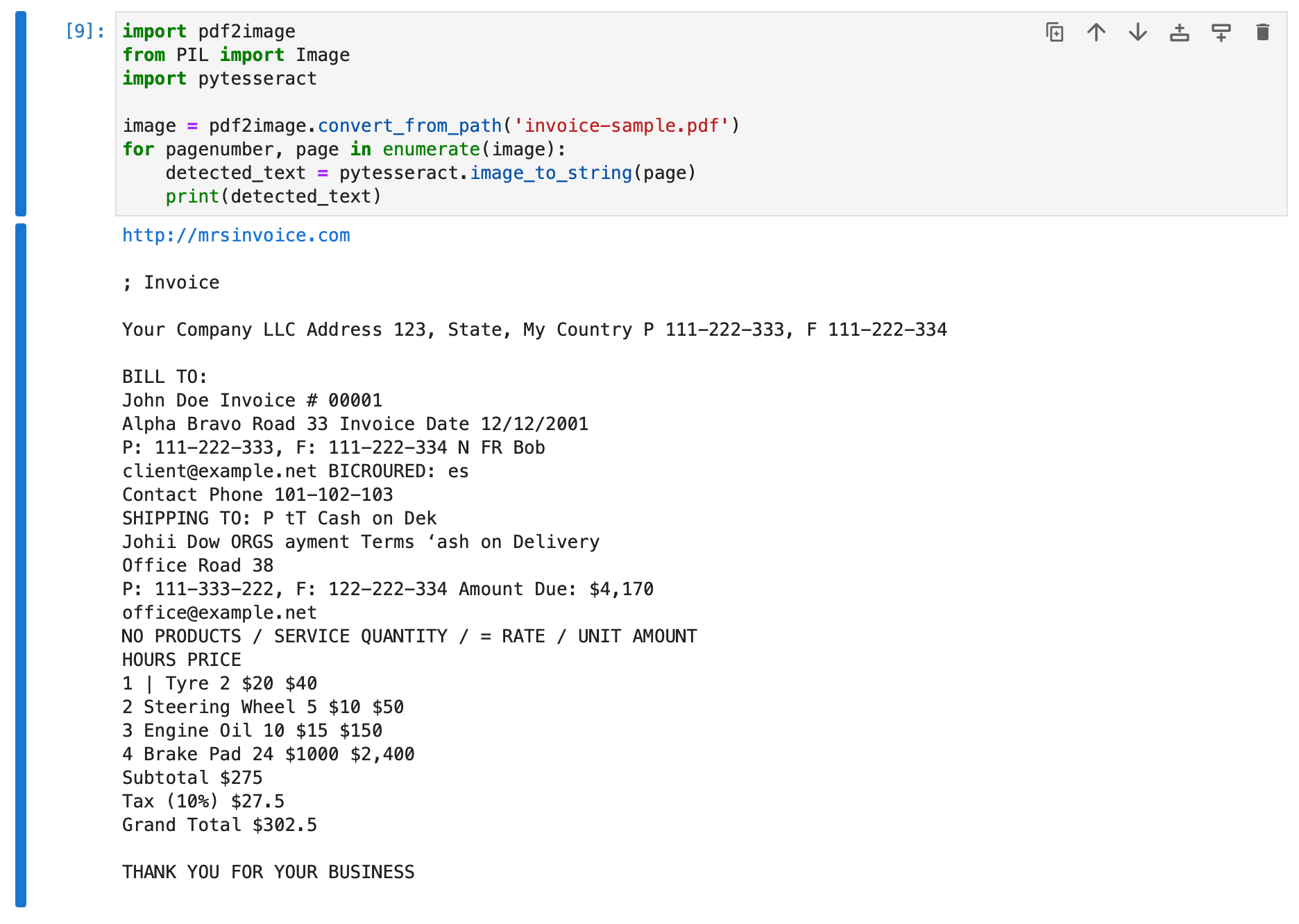
We can see that the detected_text variable in the above code snippet has stored the text contents of the pdf file detected by the OCR engine.
If you are further interested in mastering more advanced use cases of Tesseract in Python, check out our in-depth pytesseract tutorial.
This wraps up our section on reading text from PDF files using Tesseract.
Note: If your use case is invoice OCR -
- read our blog on how to code an invoice parser. The blog guides you towards creating your own invoice parser in Python, which performs OCR on invoice pdf / image files, detects relevant features (such as invoice amount, buyer, seller, date of invoice, etc.), and extracts them in a structured format.
- If you want an automated hassle-free software which performs invoice OCR and feature extraction seamlessly using advanced AI models, try Nanonets Invoice OCR.
- For other advanced OCR use cases and their solutions, explore our Products and Solutions using the dropdowns at the top right of the page.
Have an OCR problem in mind? Want to reduce your organization's data entry costs? Head over to Nanonets & build OCR models to start automating manual effort & processes using advanced AI.
Have an enterprise OCR / Intelligent Document Processing use case ? Try Nanonets
We provide OCR and IDP solutions customized for various use cases - accounts payable automation, invoice automation, accounts receivable automation, Receipt / ID Card / DL / Passport OCR, accounting software integrations, BPO Automation, Table Extraction, PDF Extraction, and many more. Explore our Products and Solutions using the dropdowns at the top right of the page.
For example, assume you have a large number of invoices that are generated every day. With Nanonets, you can upload these images and teach your own model what to look for. For e.g., in invoices, you can build a model to extract the product names and prices. Once your annotations are done and your model is created, integrating it is as easy as copying 2 lines of code.
Here are a few reasons you should consider using Nanonets:
- Nanonets makes extracting text easy, structuring the relevant data into the fields required and discarding the irrelevant data extracted from the image.
- Works well with several languages
- Performs well on text in the wild
- Train on your own data to make it work for your use case
- Nanonets OCR API allows you to re-train your models with new data with ease so that you can automate your operations anywhere faster
- No in-house team of developers is required
Visit Nanonets for enterprise OCR and IDP solutions.
Sign up to start a free trial.
Free Online OCR Tools
There are a bunch of free online OCR tools that can be used for performing OCR online. It simply means uploading your input files, waiting for the tool to process and give output, and then downloading the output in the required format.
Here is a list of free online OCR Tools that we provide:
Have an OCR problem in mind? Want to reduce your organization's data entry costs? Head over to Nanonets & build OCR models to start automating manual effort & processes using advanced AI.