
Ever snapped a photo of a document or note, only to realize you can’t edit, copy, or even search the text? It's frustrating, right? Whether you’re organizing handwritten project notes or digitizing receipts to track expenses, having the text trapped in an image isn’t helpful.
OCR (Optical Character Recognition) has made this process easier, converting printed, handwriting to text, or even scanned content into editable and searchable digital formats in seconds. Whether you’re dealing with messy handwriting, complex tables, or even checkboxes, modern OCR tools leverage cutting-edge machine learning and computer vision to make text extraction seamless.
In this guide, we’ll show you how to extract text from images effortlessly. From manual hacks to advanced automated OCR platforms, you’ll find the best method to save time and get the job done efficiently. Let’s dive in!
How to extract text from image files?
There are a few ways to achieve this. For ease of understanding, we are segmenting all the ways one can use to extract text from images into 3 types:
- Manual methods: As the name indicates, these methods can be employed for image to text conversion by any individual and don’t have a lot of prerequisites. They can be executed by your standard workplace tools, like G-Suite, or MS-Suite and an internet connection. These are suitable for one-off or occasional conversions and cannot handle large volumes of images. Even so, most of them are slow, tedious and generally inefficient.
- Semi-automated methods: These methods involve leveraging more advanced technology than the standard workplace toolkit in a crude manner. They are more efficient than manual ones but fail to handle enterprise level volumes or highly specific consumer needs. They also require some degree of coding proficiency for execution and even then, may not produce the desired results.
- Automated methods: These typically involve leveraging cutting edge technology like, Machine Learning (ML), Natural Language Processing (NLP), and Optical Character Recognition (OCR). They automate the process of extracting image to text completely and can go beyond just that to process extracted data, automate import and export of images as well as integrate with other software for a seamless experience. There are specialized vendors and/or tools that can handle this process completely.
Now that we understand the segmentation of these methods, we can dive deeper into each of these categories with examples. Let’s start with looking at the manual methods of converting Images to text.
1. Manual Methods
In this section, we will cover the manual methods that one can employ for a quick conversion of an image file into text. There are primarily 3 methods we will be talking about, extracting text from an image by converting it into a PDF, using MS-Word and using Google Drive.
a. Extract text from an image by converting it into a PDF
By first converting an image into a PDF file, you can copy text from it pretty easily in some cases.
- Pick an appropriate image to PDF converter from Adobe Acrobat online - e.g. the JPG to PDF converter (supported image file types include JPG, PNG, BMP, and more).
- Click "Select a file" to upload your image, or drag and drop it onto the converter.
- Click open the downloaded PDF file.
You can now copy the text from the PDF.
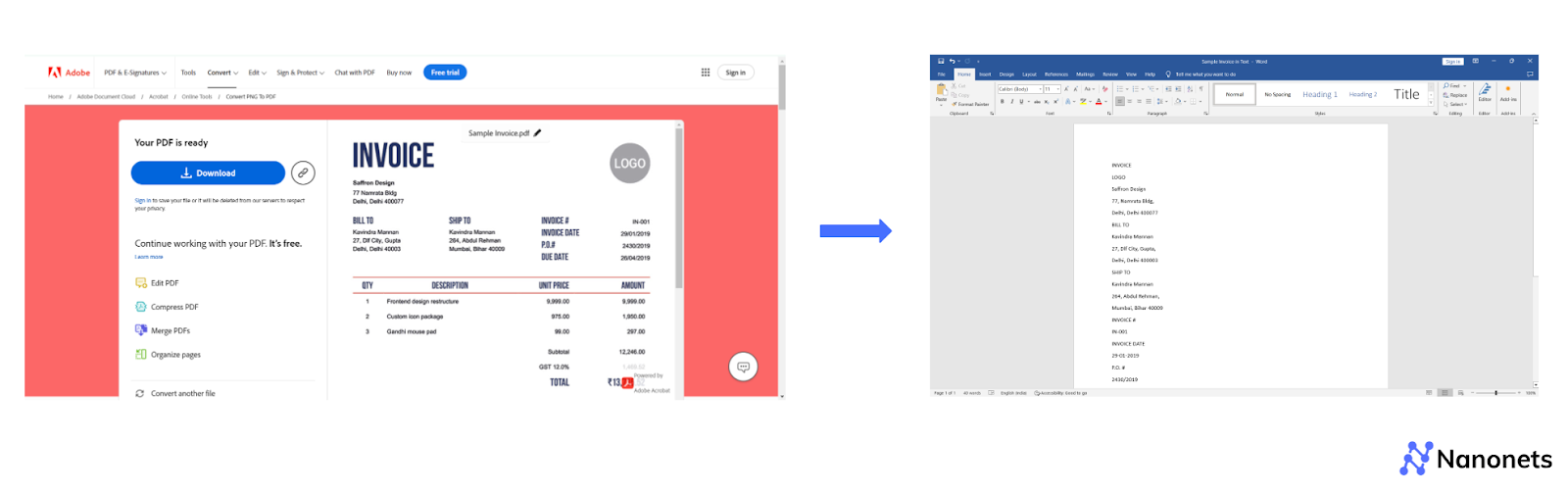
In certain cases, the converted PDF might turn out to be flat and you might not be able to copy the text readily! Even if you can, you run the risk of losing formatting, like, tables, etc.
You might have to use PDF to text converters for extracting text in that case.
b. Convert a picture to text on Microsoft Word
Converting picture to text in Word also involves an intermediary step of converting the file to a PDF format.
- Save the Image you want to convert as a PDF file.
- On Microsoft Word, click File >> Open >> Browse and select the PDF file you want to convert to a Word document.
Microsoft Word will automatically detect the text in the PDF and display it as editable text on a new Word document. It might take some time for the conversion to be completed.

While this method works fine, text formatting might get modified - especially if your initial image contained complex tabular data or check boxes for example. There are occasional errors or misinterpretations induced in the converted data.
c. Extract text from images in Google Drive
Google Drive allows you to open any image (or PDF) file on Google Doc, thus rendering the text in an editable Doc format.
- Upload your image on Google Drive.
- Right-click the file >> Open with >> Google Docs.
It may take a while but you'll eventually get a Google Doc with both the original image file and the extracted text in an editable format.
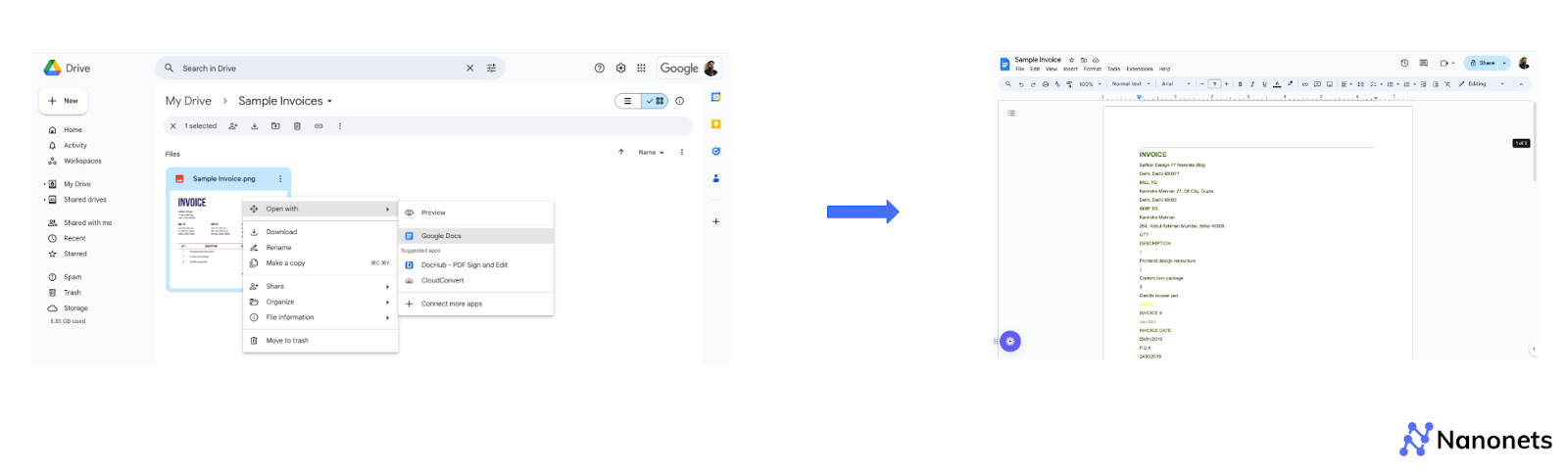
Like in the previous method, text formatting might be lost when converting an image to a Google Doc in this manner - especially if your initial image contained columns or tables for example.
2. Semi-Automated
Now that we have covered the manual methods for converting an Image to text and also looked at the significant drawbacks of using them, let’s take a look at the next segment of methods. These are semi-automated methods that employ open-source OCR libraries to first extract the text from images and then use LLMs (Large Language models) to process the extracted text. These methods require some coding proficiency and still may not produce the desired results. However, it is important to have a quick look at them.
a. Convert image to text using open-source OCR libraries
In this section, we will be looking at how to extract text from images using open-source OCR libraries, like Pytesseract from Google.
Tesseract is an open source Optical Character Recognition (OCR) engine designed and maintained by Google. Pytesseract is a Python library that forms the interface for us to access Tesseract.
We can further process this text using Large Language Models (LLMs) to extract specific data points, analyse, summarise, or translate the extracted text. This process consists of two steps:
- Extract text from images using Pytesseract
- Process the extracted text using LLMs (Large Language Models)
Large Language Models (LLMs) are an advancement on Natural Language Processing (NLP). They are sophisticated Machine Learning models that are trained on large data sets and use complex neural network architectures to mimic human problem solving. They are capable of performing a wide range of language-related tasks with accuracy and fluency in a prompt-and-response manner.
Prerequisites:
- Make sure you have an OpenAI API key
- Make sure you have the correct libraries installed, pytesseract, PIL (pillow), and openai. You can run the following command to do so:
pip install pytesseract pillow openai
Code Snippet:
from PIL import Image
import pytesseract
import openai
# Define function for OCR text extraction
def extract_text_from_image(image_path):
# Load the image from the file path
image = Image.open(image_path)
# Perform OCR on the image to extract text
extracted_text = pytesseract.image_to_string(image)
return extracted_text
# Define function to extract information using GPT-4
def extract_info_with_gpt(extracted_text, api_key):
# Define the prompt for GPT-4 to extract specific information
prompt = f"""
Extract the following information from the invoice text below:
1. Invoice Number
2. Amount
3. Due Date
Invoice text:
{extracted_text}
"""
# Initialize OpenAI API
openai.api_key = api_key
# Use GPT-4 to extract the information
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
max_tokens=100
)
# Extracted information from the response
extracted_info = response.choices[0].message['content']
return extracted_info
def main():
# Path to the image file
image_path = 'your-image-path'
# Your OpenAI API key (replace with your actual key)
api_key = 'your-api-key'
# Step 1: Extract text from the image using OCR
extracted_text = extract_text_from_image(image_path)
# Step 2: Extract specific information using GPT-4
extracted_info = extract_info_with_gpt(extracted_text, api_key)
# Output the extracted information
print("Extracted Information:")
print(extracted_info)
# Run the main function
if __name__ == "__main__":
main()Leveraging such open-source libraries for crude extraction of text from images may not always produce the desired results. It fails when it encounters columnar data, complicated tables and cannot handle features like, signature or checkbox detection. It is also unfeasible for handling enterprise-level volumes.
3. Automated
The next segment of methods are the completely automated methods that leverage cutting-edge technology like Optical Character Recognition (OCR) and Large Language Models (LLMs) all combined into a seamless interface to convert multiple images to text online.
These methods outsource the process to third-party tools or Intelligent Document Processing (IDP) software that can automate import of these images, conversion to text, post processing of data as well as integration into other software. They also provide enterprise-grade security, SLAs around uptime and features like, signature detection, checkbox detection, etc. that come in handy when dealing with standard images, like invoices or bank statements or legal contracts. They can comfortably handle large volumes of images as well.
a. Convert image to text using IDP software
Intelligent Document Processing software (IDP) is a class of software that leverages Optical Character Recognition (OCR) technology to extract text from a variety of file formats including Images. They can take it one-step further and automate this entire workflow of extracting text from images, including, importing images, extracting text from them and processing it as well as exporting it to other software.
One such software is Nanonets, which uses advanced Optical Character Recognition capabilities to extract text from pictures/images as well as documents.
This goes beyond the basic OCR that comes as part of the methods covered above. It can extract text from documents and images pretty accurately - even ones with complex data formatting. Such OCR software can not only maintain the original formatting of the text in the image, but also extract just the structured data that you need. For those who want to experience a simpler, one-step process, Nanonets also offers an online Image to Text tool that you can try instantly. This tool provides a quick and easy way to extract text from images, perfect for smaller-scale tasks or getting a flavor of what the full IDP solution can offer.
Here's how you can convert image to text using Nanonets:
- Upload or automatically ingest images from emails, cloud storage services, support tickets, and just about any data source.
- Extract text or data accurately with advanced AI-powered OCR extractors that don’t rely on predefined templates.
- Export clean structured data as XLS, CSV, or XML etc. or push data into your CRM, WMS, or database directly.
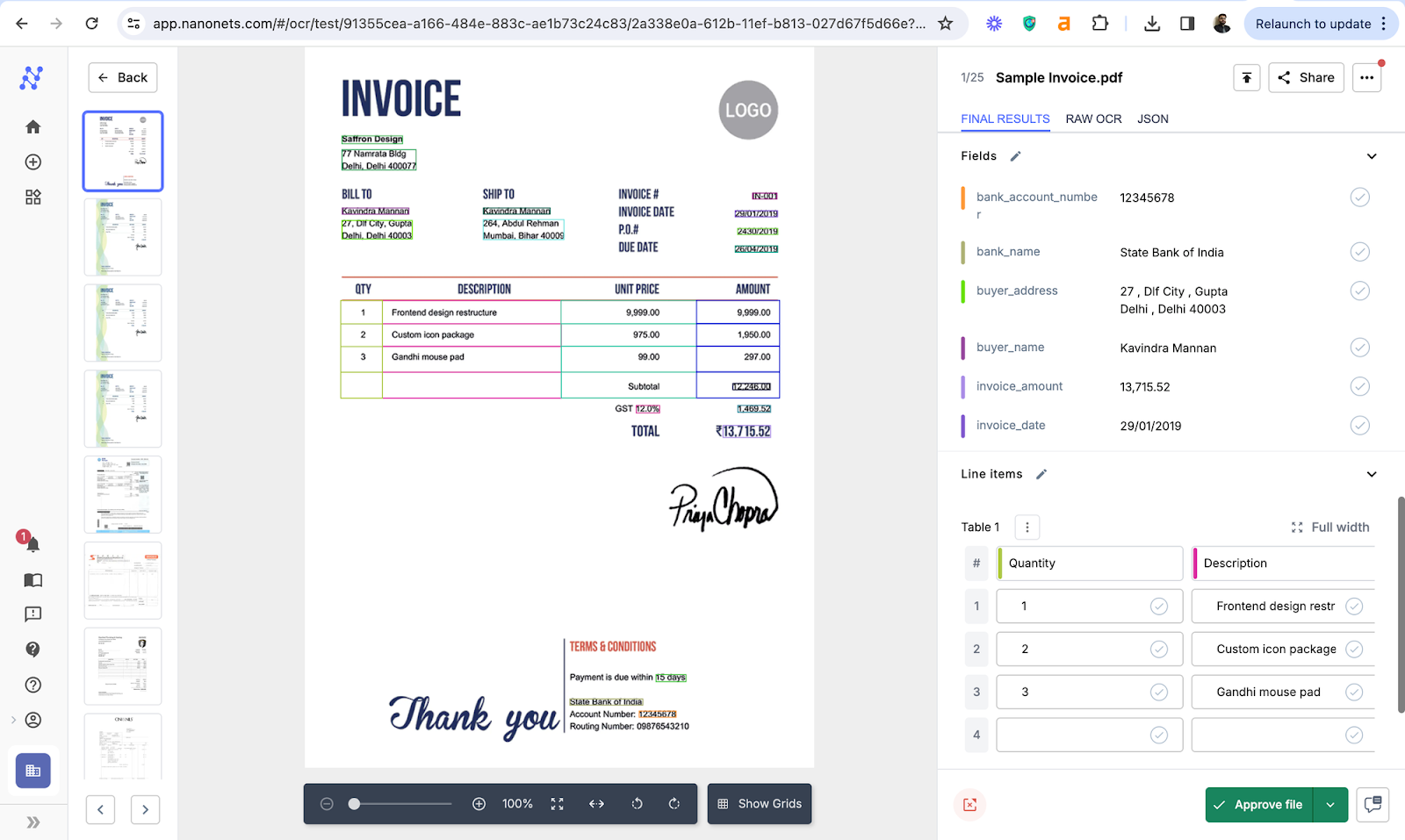
Complete workflow automation with minimal to no human interference.
Can handle large volumes.
Can retain source formatting, such as, complex tables, among other things.
Provides advanced features, like, signature detection, checkbox detection, etc.
Why convert images to text or extract text from images?
Extracting text from images is a pretty common requirement - both for personal and business use cases. Here are a few reasons why converting an image document to text might be beneficial:
- Textual data in digital format is more convenient to store, edit, organize, search or even copy.
- Copying text from images is a much more efficient alternative to manual data entry - especially when dealing with images with lots of complex tabular text or handwritten data.
Additionally when using software (such as OCR) for image to text extraction, you can process multiple images simultaneously or in batches thus saving a lot of time and effort.
How to ensure accurate text conversion from an image?
Here are a few things to keep in mind while selecting the most appropriate image to text extraction method for you and minimizing any potential rework:
- The image or picture needs to be clear with legible text - blurred or dark images with tiny non-standard text fonts might affect accuracy
- Try to maintain a standard orientation for the images - skewed images might against affect the accuracy of the text extraction
- The file size of images shouldn't be Too large or too small - e.g. Google Drive ideally recommends image files smaller than 2MB
- If maintaining the original text formatting from the image is crucial, then select an appropriate method for you - not every image to text conversion method can guarantee this!
- Always review the extracted text - or a sample at least - for accuracy. While simple text extraction is pretty straightforward, errors can occur with images of more complex documents (invoices, bank statements, contracts etc.).