PDFs are a great choice for viewing, sharing and preserving data - the perfect file format to lock in data. However, to extract data from PDF for further processing or data analysis can be extremely challenging.
This is one of the main reasons that PDF documents are often converted to the CSV (Comma-Separated Values) format. It's so much easier to edit, manipulate and analyse data directly on a CSV file or import the CSV into spreadsheet applications such as Excel or Google Sheets.
- Data is presented in a neat structured format with each line representing a row of data and commas separating the individual values within each row
- CSVs are compatible across most spreadsheet tools, databases, and statistical analysis software
- Most ERPs, accounting software, CRMs and business intelligence systems readily import CSVs for smooth data integration
- Allows for scripted processing of data from regular PDF reports
In this article, we cover some popular methods of converting PDF files to CSV and also look at a few advanced techniques meant for more complex PDF to CSV conversion use cases.
How to convert PDF to CSV with Adobe Acrobat
Adobe Acrobat is the go-to platform for viewing and managing PDFs.
While it does offer a native CSV export option, Adobe's own documentation recommends that PDFs should ideally be converted to an Excel format first and then saved as a CSV. This reduces the chance of formatting errors.
Here are the steps:
- Open Adobe Acrobat. You'll need the desktop version of Adobe Acrobat for this method.
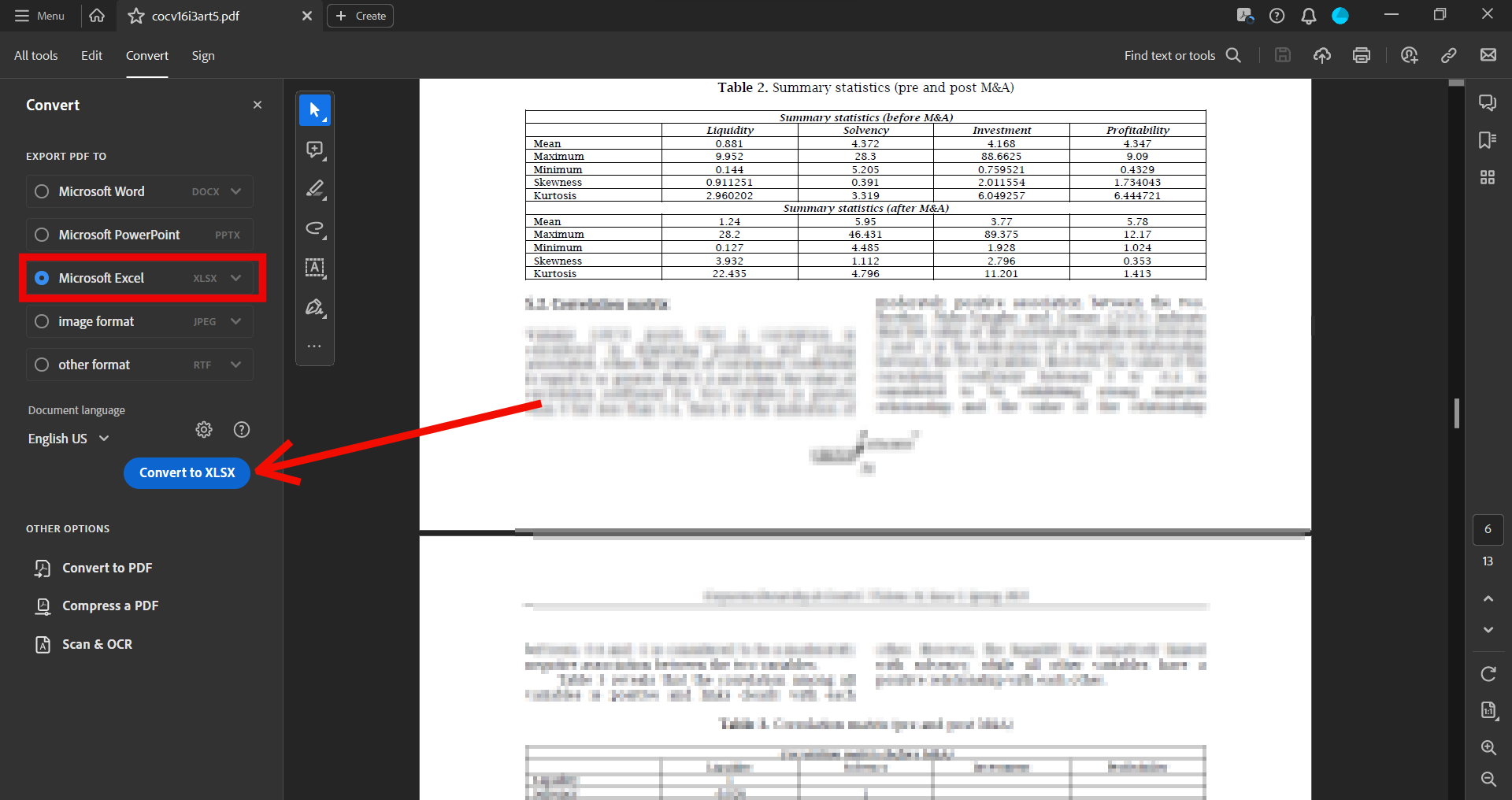
- Open and export as Excel. Open the PDF file you want to convert and click Tools > Export PDF > Select the Excel format (.xlsx) from the drop-down menu.
- Save as Excel. Click "Export" and choose a location to save your converted file.
- Open and save as CSV. Open the Excel file, review the formatting and check for errors the click File > Save As and choose CSV (.csv) from the drop-down menu.
How to convert PDF to CSV with Google Docs
For folks who don't have a paid subscription to Adobe Acrobat, you could try a slightly roundabout way to convert a PDF document to CSV using Google Docs.
Here are the steps:
- Upload PDF on Google Drive. Click "New" > File upload > and select the PDF file that you wish to upload.
- Open PDF on Google Docs. Double click to open the PDF file on Google Drive > Open with Google Docs
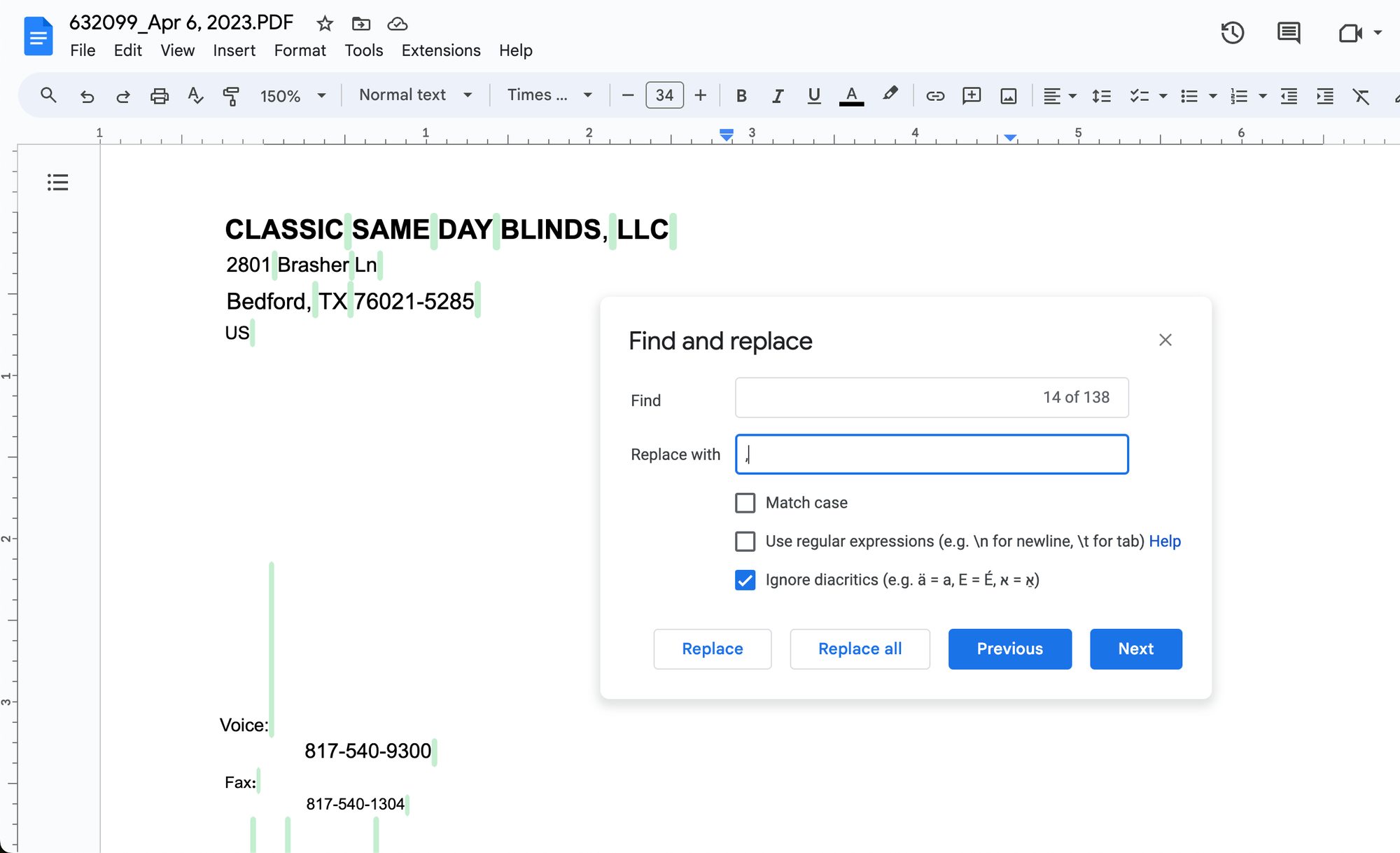
- Convert text data into comma-separated values. Open the "Find and Replace" dialog box (Ctrl+F or ⌘ + F). Replace all spaces in the text with a comma (,).
- Download as .txt and rename to .csv. Click File > Download > Plain text (.txt). Rename the file extension of the downloaded file from .txt to .csv to convert the file to CSV.
How to convert PDF to CSV with online converters
The fastest way to convert PDF files into CSV files is to use a dedicated online converter such as Zamzar or Convertio, among others. Simply upload a PDF and download the converted CSV in a few seconds.
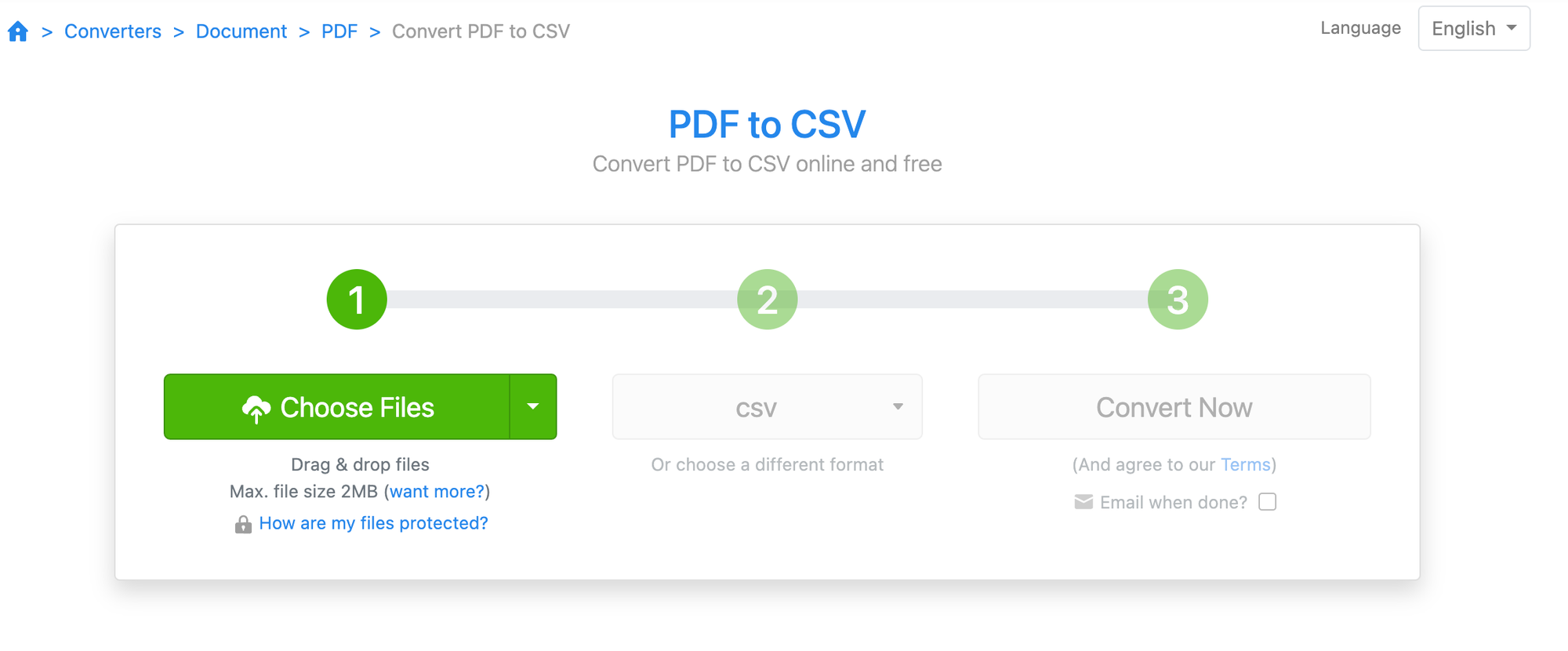
Here are the steps for Zamzar:
- Upload PDF. Click "Choose Files" > and select the PDF file that you wish to upload.
- Download converted CSV. Click "Convert Now" > wait for a few seconds > and click "Download" to get the converted CSV file.
How to convert PDF to CSV using Python libraries
So far, we've mostly looked at methods that work well for one-time PDF to CSV conversion use cases. They are not ideal for frequently converting a large number of PDF documents to CSV.
Python libraries such as tabula-py and camelot are ideal for batch processing and automating PDF to CSV conversion workflows.
Tabula-py is generally easier to use and faster, while camelot offers more fine-grained control and can handle complex table structures better.
Here are the steps to convert PDF files to CSV using tabula-py:
- Install tabula-py:
pip install tabula-py- Here's a Python script to convert all pages of a PDF to a single CSV file using tabula-py:
import tabula
# Path to your PDF file
pdf_path = "path/to/your/pdf/file.pdf"
# Convert PDF to CSV
tabula.convert_into(pdf_path, "output.csv", output_format="csv", pages="all")
print("Conversion completed. Check output.csv")- If you want to extract tables from specific pages or have more control over the process, you can use the
read_pdf()function:
import tabula
import pandas as pd
# Path to your PDF file
pdf_path = "path/to/your/pdf/file.pdf"
# Read PDF into a list of DataFrames
dfs = tabula.read_pdf(pdf_path, pages="all", multiple_tables=True)
# Combine all DataFrames and save to CSV
combined_df = pd.concat(dfs, ignore_index=True)
combined_df.to_csv("output.csv", index=False)
print("Conversion completed. Check output.csv")Now, let's look at how to use camelot to convert PDF files to CSV:
- Install camelot-py:
pip install camelot-py[cv]- Here's a Python script to convert a PDF to CSV using camelot:
import camelot
import pandas as pd
# Path to your PDF file
pdf_path = "path/to/your/pdf/file.pdf"
# Read tables from the PDF
tables = camelot.read_pdf(pdf_path, pages="all", flavor="stream")
# Combine all tables into a single DataFrame
combined_df = pd.concat([table.df for table in tables], ignore_index=True)
# Save the combined DataFrame to CSV
combined_df.to_csv("output.csv", index=False)
print(f"Conversion completed. Found {len(tables)} tables. Check output.csv")Camelot offers two parsing methods: 'stream' and 'lattice'. The 'stream' method is generally faster and works well for most PDFs, while 'lattice' is better for PDFs with clearly defined borders.
- If you need more control or want to process tables individually:
import camelot
import pandas as pd
pdf_path = "path/to/your/pdf/file.pdf"
# Read tables from the PDF
tables = camelot.read_pdf(pdf_path, pages="all", flavor="stream")
# Process each table individually
for i, table in enumerate(tables):
table.to_csv(f"table_{i+1}.csv")
print(f"Conversion completed. Extracted {len(tables)} tables.")How to convert PDF to CSV using an LLM
If you're someone like me, who isn't comfortable working with Python libraries or anything remotely associated with coding/programming, conversational LLMs such as Claude AI or ChatGPT offer a much more straight-forward alternative.
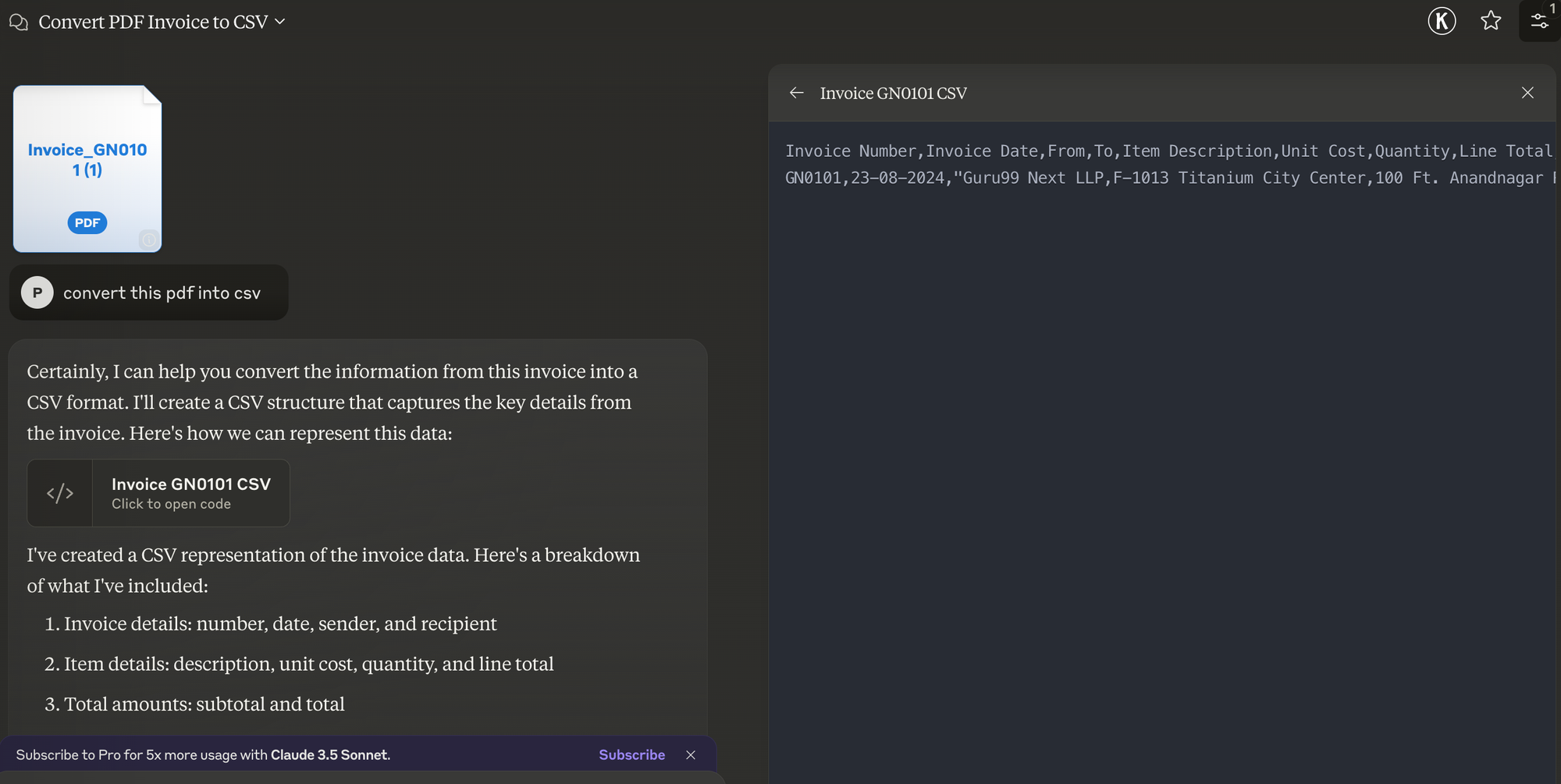
Here are the steps to convert a PDF file to CSV on Claude:
-
Upload and add a prompt. In the dialog box, enter something like "convert this PDF file into a CSV file"
-
Review and download. Claude will share the converted document in a few seconds along with a few insights regarding the original PDF file.
How to convert PDF to CSV using Nanonets or IDP software
All the methods we have covered so far will probably struggle with converting complex PDFs to CSVs. And setting up an automated PDF to CSV conversion system using any of the methods above might not be very straightforward either.
Intelligent document processing solutions, like Nanonets, offer the best approach to converting complex PDFs into CSVs.
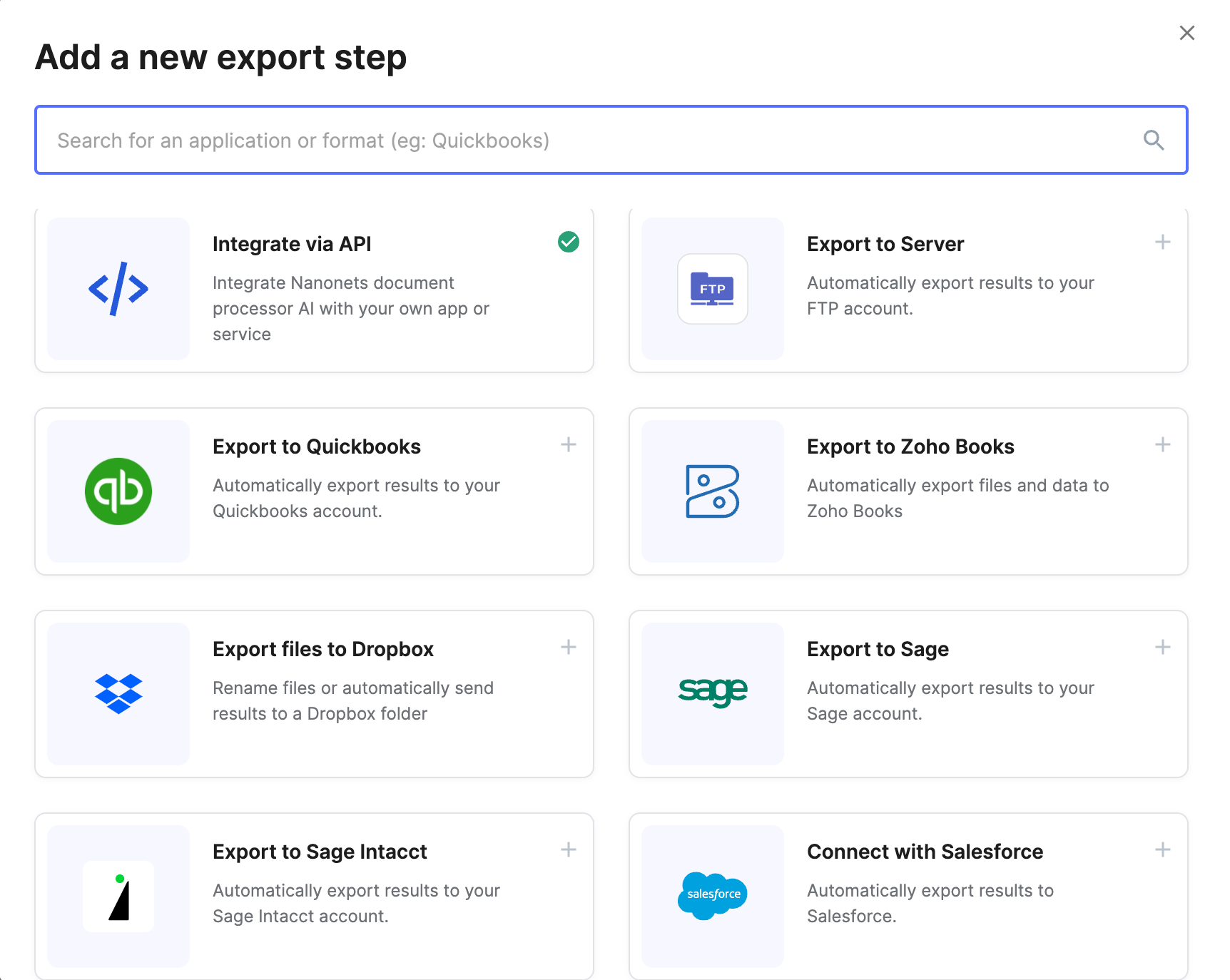
They are also ideal for setting up completely automated workflows or direct integrations into ERPs, accounting software or CRMs (a common reason for converting into CSV, in the first place).
Here are the steps to convert PDF files to CSV on Nanonets and automate the entire process:
- Signup and login. Create your Nanonets account and log in.
- Select the workflow. Select an appropriate workflow. Nanonets offers pre-built workflows for popular business documents (invoices, receipts, BoLs etc.) and a zero-shot AI extractor that can "understand" any complex document.
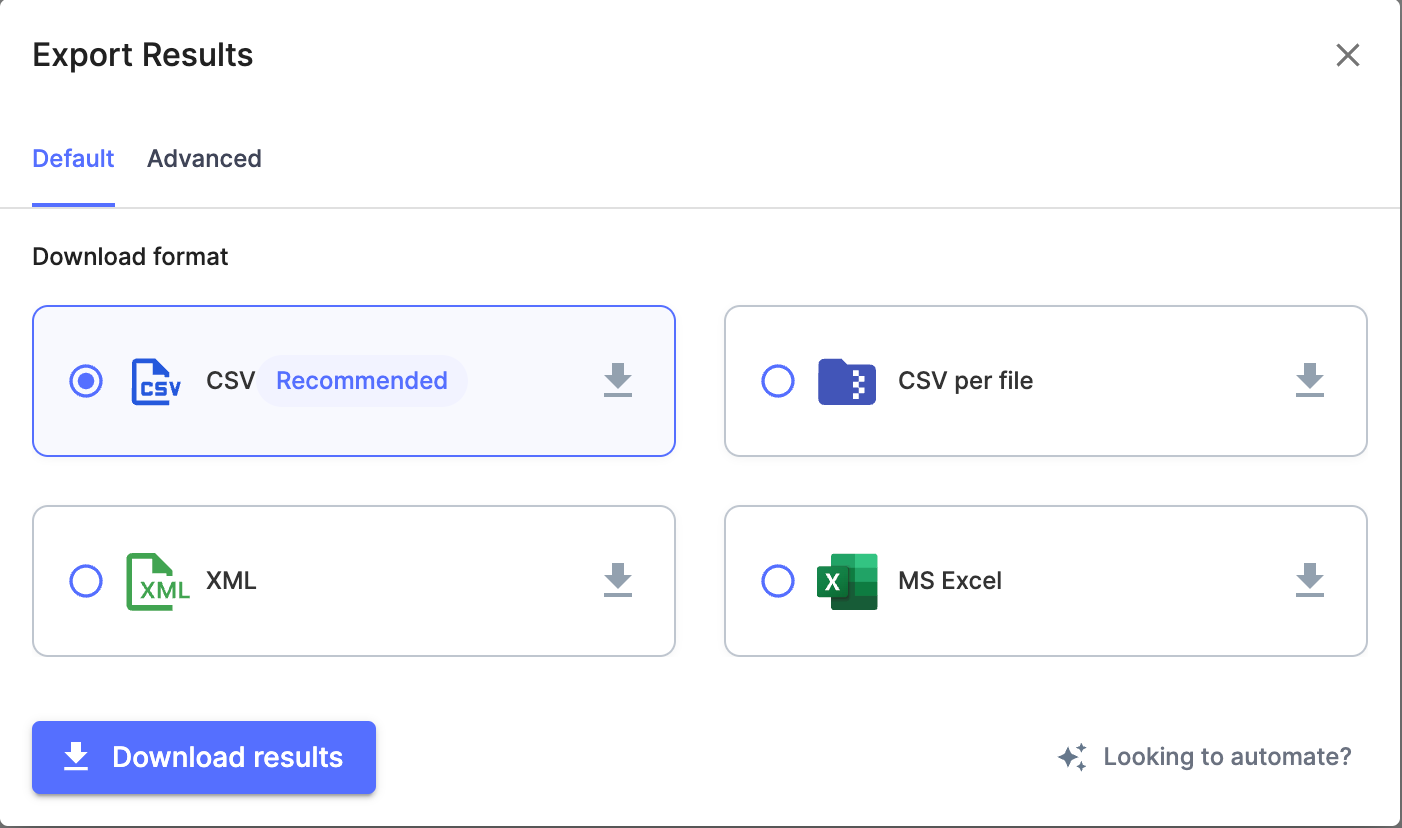
- Export. Export results in bulk as CSV. Or integrate with ERPs, CRMs or accounting software directly.