

Summary: Learn to parse information from files. Explore OCR usage, programming languages, and automation. Discover real-world examples & workflows for efficient file parsing.
We live in a digital world, generating unlimited amounts of data every day. Many users have access to this raw data in different forms such as documents, images, videos, HTML pages, etc. The ability to extract essential information from this data will decide whether we can generate a compelling advantage for our business with this data.
However, automating the information extraction process is challenging when dealing with a vast amount of data. Furthermore, as the data accumulation increases, so does the need to read and understand it. This is where data parsing come into the picture. In simple terms, parsing data can help turn unstructured data or unreadable data into more readable and valuable information.
Let's take a deep dive into parsing different data types using various tools and techniques (especially with OCR). Additionally, we'll be discussing a few document parsing and data parsing business use cases that can help automate and create workflows on top of your existing data. Below are the topics we'll be covering in this article:
Let's get started!
How to Parse Information from Files?
Before we answer how to parse information from files, let's first learn the Data Parser fundamentals.
A data parser helps us turn unstructured data/un-readable data into structured data. Data Parsers are also used to convert data from one type to another.
For example, let's assume we have an HTML file, and we would need to convert it into a PDF file. In this case, we could use a data parser that parses (reads) through the HTML file, extracts the necessary information and exports it to the PDF file.
Similarly, there are several problems that a data parser could solve when dealing with massive amounts of data - e.g. email parsing, extracting phone numbers or extracting emails.
These parsers are usually programmatically built based on particular data to read, analyse, transform, and provide more structured results. Now, with lots of open-source technologies and several active programming communities, we could find several data parsing tools online that can automate several business use-cases for free. However, when the data is complex, we might need to write some additional rules and conditions, which are sometimes challenging.

Now, let's look at some of the essential concepts needed for parsing information from files.
Components of a Parser: Components are different types of syntax we find in data. For example, these can be unique characters, white space, regular expressions and many more. Therefore, when building a parser, we need to define all the rules to identify all these types of components.
Grammar: The structure of data might not be the same for all the data. Therefore, for a parser, we define grammar which are rules used to describe a language. It has several elements that can identify expressions, missing tokens etc.
Algorithms: Parsers have different algorithms that each have their strengths and weaknesses. Usually, there are two strategies; top-down parsing and bottom-up parsing. Both are defined using the parse tree as generated by the parser.
A top-down parser functions to identify the root of the parse tree first and then goes to the subtrees and then the tree's leaves. In comparison, a bottom-up parser begins from the bottom of the tree and works its way up until the tree's root. This is how usually we parse through different kinds of files.
Here are some of the common examples of how parsers can help extract data or convert data:
- Convert HTML data into readable data
- Export data from PDF files to JSON
- Parsing through email data to extract meaningful information
- Extract data or text from images or scanned data
- Get essential data from complex, nested JSON
- Key-value pair extraction from documents
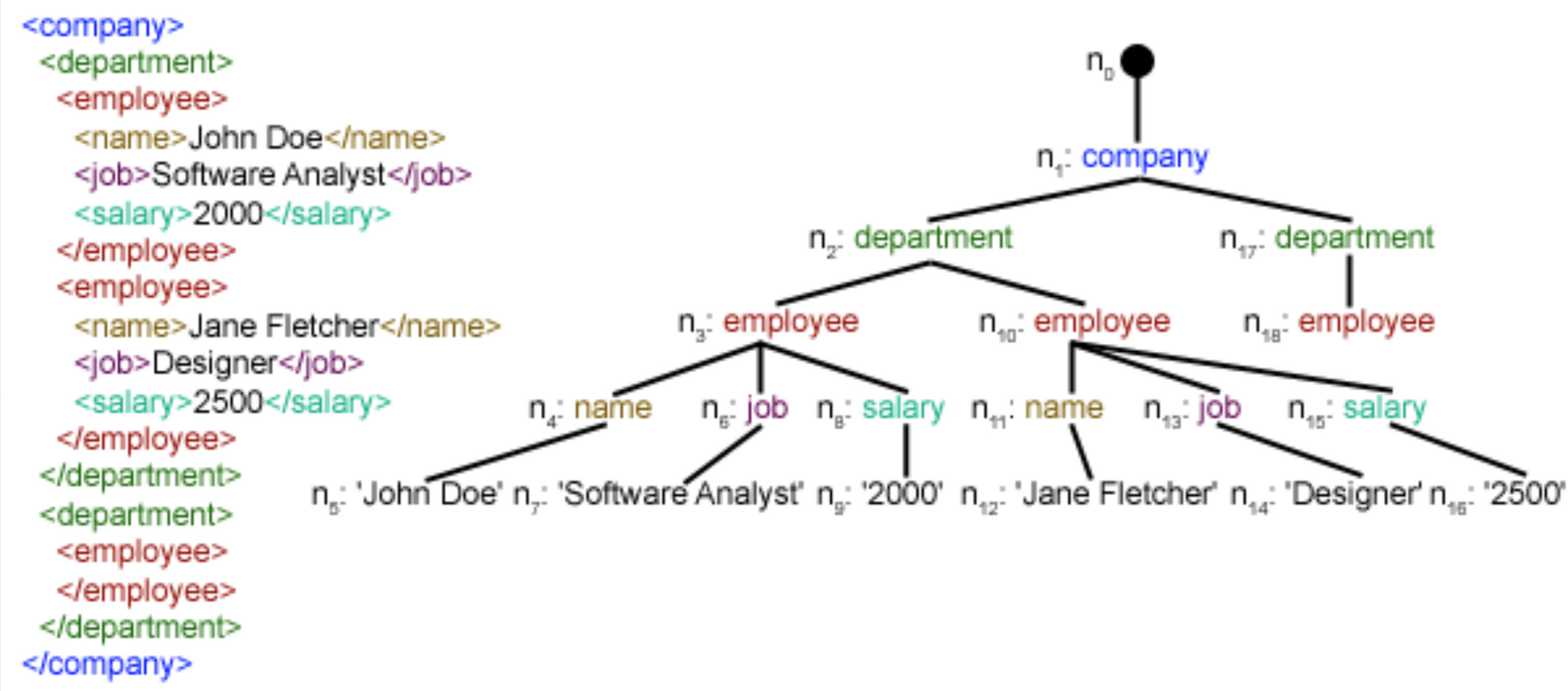
In the next section, let's look at parsing data from image files or scanned files.
Looking to parse and extract information from files? Head over to Nanonets to automate the process of parsing, extracting, exporting and organizing information from your files!
The Use of OCR in Parsing Information from Files
We often see lots of data in the form of images or scanned copies. For example, documents related to financing, corporate businesses, manufacturing industries contain lots of data that cannot be edited directly. Some sectors have started using this modern tech to extract data from images. However, many still use data-entry operators to manually store and verify all document-based information which is time-consuming and error-prone.
OCR (Optical Character Recognition) based parsers could be used to help automate this manual work of extracting data from scanned files. As abbreviated, the goal of OCRs is to recognise characters, basically text from the images, by performing several mathematical operations.
Now, let’s consider a real-world example:
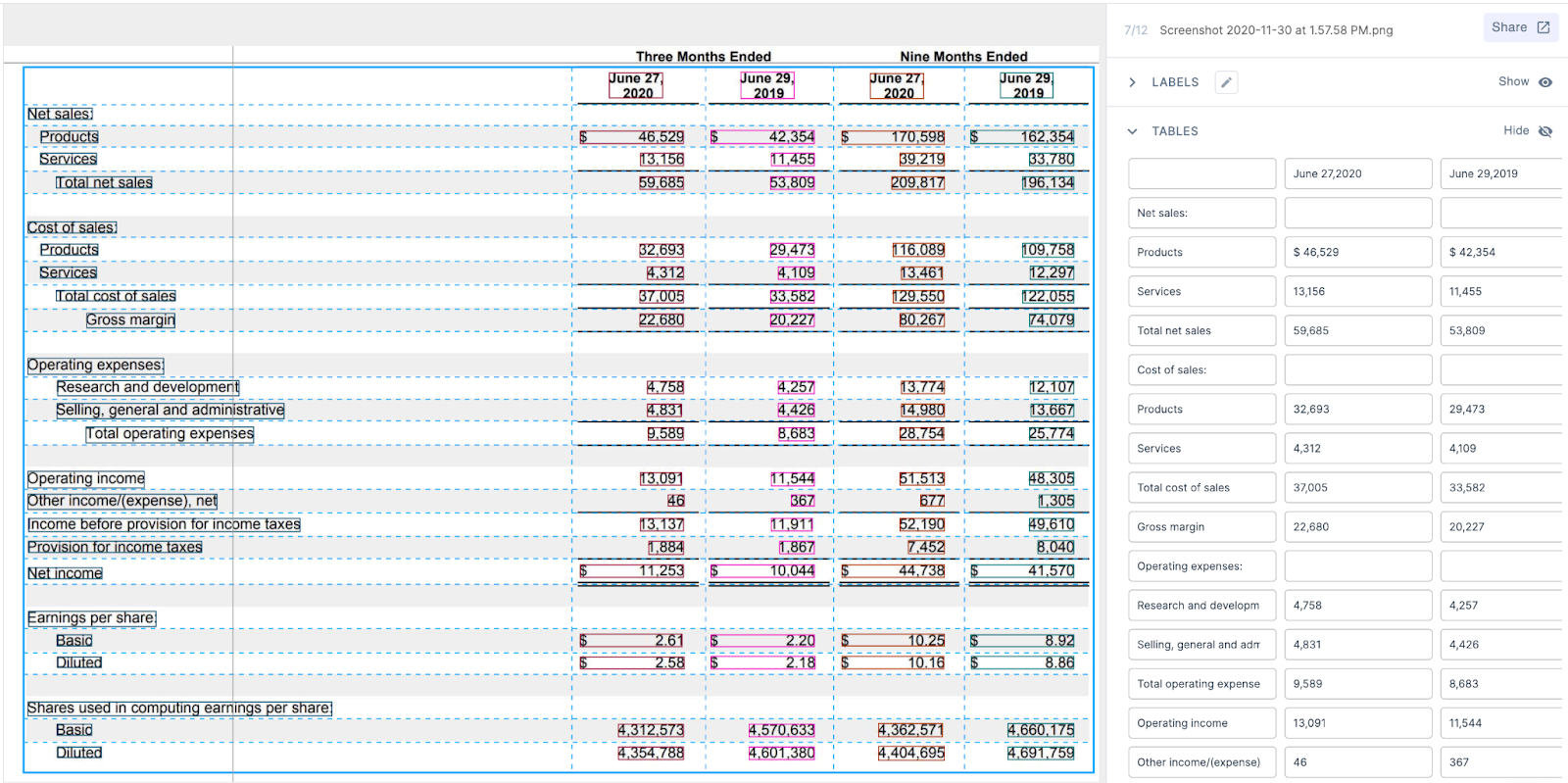
Let’s say we need to save and analyse all the scanned receipts collected at a particular store. Usually, without OCRs, the only option is to enter all the data manually, but with OCR, we could pull out all the text from the receipt. However, the data from the OCR is not straightforward. It has much unprocessed and unrelated information such as text coordinates, special characters and unwanted spaces. This is where parsers can help read the data and make them more structured. Below is a screenshot of one of the workflows in which users’ OCRs and parsers extract meaningful data.

In the above image, first, a receipt is digitised using an OCR. The output from the information is usually in a key-value pair, which isn't great to read with lots of information. These key-value formats are broken down into strings with simple serialisation techniques. Next, Natural Language Processing (NLP) based tagging algorithms such as Named-Entity-Recognition (NER) is utilised to identify the necessary tags; for example, these can be receipt id, receipt items, total, taxes etc. Lastly, we bring in the parser to convert the BIO tags into readable key-value pairs.
This is how a typical workflow looks for simple data. We could utilise popular OCR tools like Tesseract or techniques like zonal OCR, which is free and open-source. However, when the data is not generic, or say if we have invoices with multiple templates, we might need a powerful OCR that can handle fonts, text alignments, noisy images, tables, and many more.
Parsing Files Using Different Programming Languages
So far, we’ve learned what a data parser does and looked at some use-cases. This section will look at how we can utilise different programming languages and frameworks to build them. Firstly, before choosing a programming language or a tool, we’ll need to review our data. If we’re working on more analytical data that needs deep-parsing and lots of cleaning, Python is a good choice as there are many data-analysing and parsing libraries. But, when working on giant datasets, Python might not be a great fit if we search through terabytes of data, as it’s a bit slow in execution. In such cases, languages like C and C++ are more valuable. Now, let’s dive into each of these programming languages and learn about their advantages and disadvantages.
Python: Python has been one of the most loved for tasks like working on data. It’s simple, fast, and easily deployable. There are several libraries in Python that can be utilised to build a data parser. Some popular libraries are Pandas, Numpy, and Scikit-learn. However, these libraries are widely used for performing type-conversion operations on massive datasets. For example, Pandas helps us convert complex tables, SQL files, Series into simple data frames. We can also export these data frames into any form, say SQL tables, HTML files or PDFs, with more insights from the data.
Let’s say, if our data is of JSON format, and we need to export it by building a parser into an excel sheet, we could directly import the internal JSON package. It’s convenient and straightforward to use, not just in dev environments; this is used across web apps for exporting data into JSON via database tables. Below is a simple example:
If you have a list of items and want to export it as JSON, you could use the following in Python:
my_list = ["Author: Jones", "Age: 29", "Topics: Machine Learning and AI"]
d= dict()
for i in my_list:
k,v = i.split(':')[0], i.split(':')[1]
d[k] = v
json.dumps(d)Output:
'{"Author": " Jones", "Age": " 29", "Topics": " Machine Learning and AI"}'Here, we wrote a simple for loop and iterated through the for loop; we split the string based on a special character (":") and added it into a dictionary. Next, we used json.dumps method to convert the python dictionary into a complete JSON file.
Here’s one more example on converting lines in a text file into items in an array:
lines = []
with open("file.txt") as file_in:
for line in file_in:
lines.append(line)Python has an in-built library for extracting patterns using regular expressions. Using this, we could build parsers that can be used on vast text data or any unstructured data. In documents, fields like dates, emails, pricing can be easily pulled out.
It’s this simple. However, doing the same in programming languages like C or C++ might be more time-consuming.
Parsing with OCR in Python: This is a bonus section, only in Python language, as it comes with many powerful tools for working on Images. Therefore, when we're working on image data sets and building workflows to extract data with parsers, we could utilise modules like open-cv, sci-kit-learn, and pillow to find and extract necessary text. On top of these, as discussed, we could use OCR engines like a tesseract. Also, building this for simple formatted data doesn't consume much time; all these are easy to install and can be deployed into production within minutes.
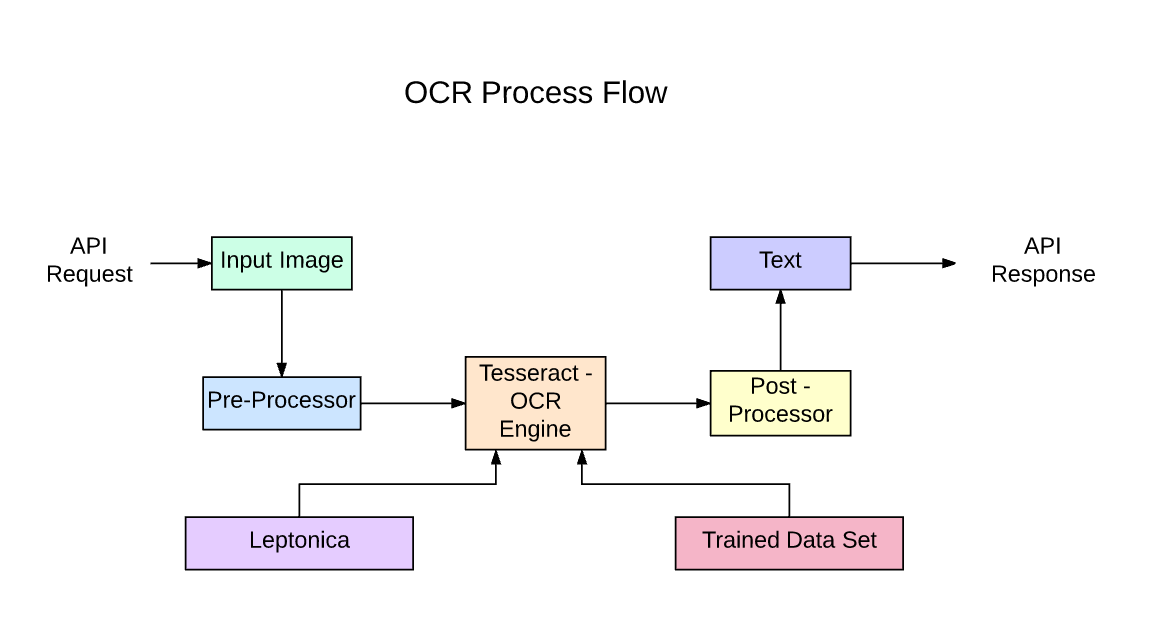
But when the images are not generic or complex regarding their layouts and text positions, we'll have to use deep learning frameworks like Tensorflow and PyTorch to build custom Deep Learning algorithms for key-value pair extraction, BIO Tagging, and NER. If you're not experienced with these, don't worry, you could always use tools like Nanonets or other third party services.
File Parsing with Java: Java is one of the most influential and robust programming languages. To date, a lot of top businesses use Java for their web applications and mobile apps. One advantage is that Java comes with a powerful scanner class that can parse through different files and does operations like search and extract. However, comparatively, the syntax might not be as handy as Python, but it still gets the job done much faster. Here's an example of how we can use the Scanner class and parse through .txt files in Java:
public class ReadFile {
public static void main(String[] args) throws IOException {
String token1 = "";
Scanner inFile1 = new Scanner(new File("file-name.txt")).useDelimiter(",\\s*");
List<String> temps = new ArrayList<String>();
while (inFile1.hasNext()) {
// find next line
token1 = inFile1.next();
temps.add(token1);
}
inFile1.close();
String[] tempsArray = temps.toArray(new String[0]);
for (String s : tempsArray) {
System.out.println(s);
}
}
}Here, we defined a simple ReadFile class. In the main function, we started by declaring a string named token to store the lines in the file while reading through it. Next, we use the in-built Scanner class and send the file name in a File instance with a delimiter. Next, we declare an array to store the lines, followed by for loop, iterating through the files and appending all the array lines. Lastly, we print the array.
This is a simple example of working on text data. When it comes to image data, Java does have tesseract support. However, the features are limited.
Automating the Process of Parsing Info or Data from Files
It’s all about reducing human effort, time and expenses for any business. For this, automation is the only solution. Now, let’s discuss some ways we can automate parsing files with modern technology.
Classic Software: Building software to automate stuff is a simple solution. This software has all the basic operations and instructions to get the job done. But, these are not scalable and extensible. The features will be limited and will be using local storage to save all the data. Therefore, a parser-based out of simple software can be used for small files that need to be regularly cleaned up. We can write conditions through which the files pass into, say, converting a simple PDF into JSON. We could use languages like Python or Java to read this file and perform specific operations and iterate it onto multiple files.
However, we can’t perform operations like parsing through tables or reading through images as they require more powerful libraries to be integrated, which might consume more computation power and data. Therefore, users prefer the cloud when it comes to parsing data from images.
Web Applications: Web applications are utilised for UI to automate the file parsing process. These choose specific backend languages like PHP, Python, Java to operate on certain types of files. All the communication between the UI, backend, and database happens mainly through the databases. If the website is served on a powerful cloud solution, OCRs can also be integrated to perform all kinds of data parsing operations. However, this solution might be time-consuming, as it involves many steps and requests to consume all across the web. Sometimes, due to confidentiality requirements, businesses opt for on-prem solutions in which the software will be a third party application, but the database can be hosted internally.
Robots and RPA: Robotic Process Automation (RPA) is one of the latest advances in automation. In RPA, robots take care of automating all the manual tasks instead of humans doing manual stuff. They are also embedded with intelligent algorithms, through which they’ll learn and minimise the error rates for every iteration. These robots can be connected with different data sources, APIs, and third-party integrations; this gives us an advantage in collecting and processing data for parsing differently.

Example Use Cases of Parsing Data from Files
In this section, we'll look at a couple of use-cases on how file data parsers can help automate manual entry for your business. We'll also be studying a rough outline of all the techniques involved for these specific use-cases.
Collecting data from invoices and receipts: Invoicing is everywhere, from small businesses, startups to giant industries and corporations. Most of these organisations use excel sheets, save these in cloud drives and manually enter them into different data formats. If we have to search through any data, it's highly impossible as most of these are saved in PDFs, PNGs or Document format. Also, many invoices contain tabular data in which details of products or services are in line items. Therefore, copy-pasting these would mess up the data format.
The ultimate solution to organise these invoice documents is to use a generic data parser to extract all the necessary information into a more readable format such as JSON or Excel/spreadsheet. But building a generic parser is challenging. Below are the essential aspects that we'll need to take care of:
- Process different types of invoices into a readable raw input.
- If there are any images or tables inside these invoices, those need to be saved separately as we'll need to run an OCR to parse through them.
- We'll need to annotate all the important invoices, such as Invoice_Id, Invoice_Type, Billed_to, Billing_Adress, Total, Taxes etc.
- Build an ideal parser with an OCR that can extract all the fields from the invoice
- Export the extracted data into either a JSON format or Excel/spreadsheet.
Digitising your invoices saves a lot of time and consumes less human work, eventually reducing the expenses spent maintaining the invoices. With expense minimisation and expedited payments, you'll have more resources to invest in innovation, hire and improve your offerings, and conduct core business operations.
Automating KYC for Financials: A lot of KYC processes slow down onboarding customers in businesses. This drives up the overhead and lacks quality control. In such cases, introducing automation can streamline, improve, and drive efficiency.
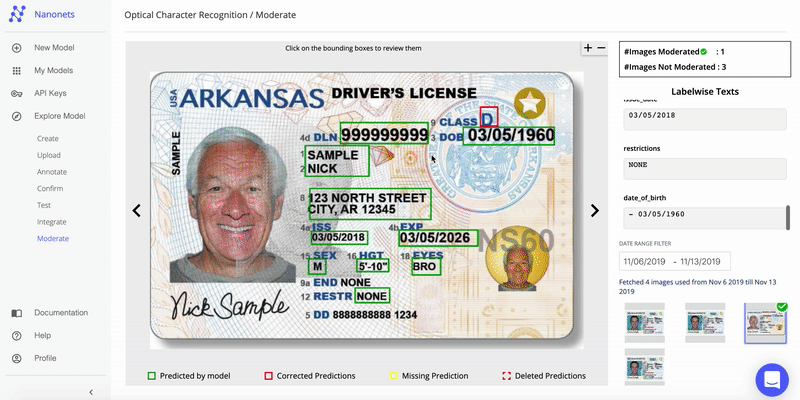
{kind=link}
Fortunately, with a file data parser, we can make automating KYC documents much more effortless. The job of the file data parser is to parse through all the customer's documents such as government-provided IDs, Professional IDs, Financial documents, etc. and store them in a much more reliable and unambiguous way. This helps the business to quickly review the customer's documents and proceed with further processing.
Below are the steps for KYC process automation with data parsers:
- Gather required documents that need to process for KYC
- Use powerful OCRs to extract all the necessary text from these documents to create a dataset
- Train deep learning-based models that can extract only necessary fields with NLP
- Use data parsers to convert the extracted text and save them in a more reliable format, for example, JSON or Spreadsheets
- Build software or export APIs that can automate this entire process
Workflows and Integrations with File Parsing
Building workflows allows us to connect with different solutions and automate processes. For example, consider the following scenario:
- We receive 10-15 emails every day that consists of invoices related to our business.
- We store all these invoices into cloud storage in a particular folder named as the date invoices are received.
- Next, we rename each of these invoices with the invoice-id and the business name.
- Lastly, set notifications to remind about invoice due dates.
Usually, doing this with a data parser takes a lot of time, and tasks like downloading invoices, uploading them to cloud storage, and renaming them with parsers can be annoying. Therefore, to automate the boring stuff, we could build workflows using different integrations.
These workflows are mostly built on the cloud, which can talk to different services using APIs and Webhooks. If you're not a developer, there are products like Zapier that can connect with your data parser and perform particular tasks. Now let's see how these webhooks and APIs work.
Workflows with APIs: Currently, almost everything that's on the web is communicated through APIs. Therefore, we can leverage these APIs to build powerful workflows and build data parsing solutions. Let's discuss a few fundamentals. First, we build data parsers for working with massive data. Therefore, the starting point is to use cloud storage for all of your data, and for this, we need not build a data centre. Instead, we can subscribe to an online cloud service and leverage APIs for your data. We can't download every file from the cloud and run OCRs to extract data, but building and maintaining one online is a complicated process. For these, we can directly connect the APIs from cloud storage to the OCR solution such as Nanonets, AWS, GCP. Additionally, you need not choose a different tech stack for these; several SDKs provide a wide range of support. Lastly, to save the output from the data parsers into the desired format, say excel spreadsheets or software, we can use the response from these APIs and transform them based on our requirements.
Here's a how the Nanonets API looks like:
Python Code: This small snippet will be taking the invoice as input and then return the crucial fields from it. We can also test this on our data; for this, we'll need to create a model on Nanonets and export it as an API using any desired language.
import requests
url = 'https://app.nanonets.com/api/v2/Inferences/Model/' + 'REPLACE_MODEL_ID' + '/ImageLevelInferences?start_day_interval={start_day}¤t_batch_day={end_day}'
response = requests.request('GET', url, auth=requests.auth.HTTPBasicAuth('Auzt3_feYVGJhuYiBUnbun5c8qQXS_rt',''))
print(response.text)Ouput:
{
"moderated_images": [
{
"day_since_epoch": 18564,
"hour_of_day": 15,
"id": "00000000-0000-0000-0000-000000000000",
"is_moderated": true,
"model_id": "category1",
"predicted_boxes": [
{
"label": "invoice_id",
"ocr_text": "877541",
"xmax": 984,
"xmin": 616,
"ymax": 357,
"ymin": 321
}
],
"url": "uploadedfiles/00000000-0000-0000-0000-000000000000/PredictionImages/0000000001.jpeg"
}
],
"moderated_images_count": 55,
"unmoderated_images": [
{
"day_since_epoch": 18565,
"hour_of_day": 23,
"id": "00000000-0000-0000-0000-000000000000",
"is_moderated": false,
"model_id": "00000000-0000-0000-0000-000000000000",
"predicted_boxes": [
{
"label": "seller_name",
"ocr_text": "Apple",
"xmax": 984,
"xmin": 616,
"ymax": 357,
"ymin": 321
}
],
"url": "uploadedfiles/00000000-0000-0000-0000-000000000000/PredictionImages/0000000002.jpeg"
}
],
"unmoderated_images_count": 156
}Nanonets Advantage in Parsing Info from Files
Nanonets is an AI-based OCR software that automates cognitive capture for intelligent document processing of invoices, receipts, ID cards and more.
Nanonets uses advanced OCR, machine learning and deep learning techniques to extract relevant information from unstructured data. It is fast, accurate, easy to use, allows users to build custom OCR models from scratch and has some neat Zapier integrations. Digitise documents, extract data fields, and integrate with your everyday apps via APIs in a simple, intuitive interface.
Here’s why you should use Nanonets as data parsers:
- Pre-processing: If your documents are poorly scanned or in various formats, you need not worry about preprocessing them. Nanonets automatically processes documents based on alignments, fonts, and image quality.
- Post Processing: You can always perform post-processing on outputs and export the data into desired formats such as CSV, Excel Sheets, Google Sheets.
- Automation: If you are working with loads of data, nanonets has some pre-installed installations using Zapier, UiPath etc.