
Key takeaways:
- Problem and solution: Manual document sorting is a major business bottleneck. AI document classification automates this slow and error-prone process by using artificial intelligence to instantly categorize files, such as invoices, contracts, and reports, thereby saving significant time and money.
- Core technology stack: Modern classification is not a single tool but a combination of technologies. It relies on OCR to digitize documents, NLP to understand the content's meaning and context, and Machine Learning models to assign the correct category with high accuracy.
- Quantifiable business impact: The ROI is significant and proven. Real-world use cases demonstrate a reduction of up to 70% in invoice processing costs and over 95% accuracy in critical workflows, such as sorting healthcare records.
- Advanced efficiency strategies: Beyond standard methods, research-backed techniques offer massive performance gains. Lightweight analysis of filenames can be up to 442x faster than full-content analysis, while sentence ranking for long documents can reduce processing time by 35% with no loss in accuracy.
- Accessible implementation: Getting started with automated document classification is more practical than ever. Modern platforms allow you to train highly accurate models with limited data (as few as 10-20 samples) and build end-to-end automated workflows in weeks, not months.
Your most diligent team members may be spending their mornings accomplishing nothing of value. They might be spending their time manually sorting chaotic inboxes and shared drives, dragging hundreds of document attachments into folders to separate customer contracts from compliance reports, as well as insurance claims from HR onboarding forms. This isn't just a minor inefficiency; it's a systemic failure to manage the unstructured data that now proliferates every level of business operations.
Here's a glimpse into why:
- 45% of employed Americans think their company's process for organizing documents is stuck in the dark ages.
- Professionals waste up to 50% of their time searching for information.
- Most SMBs spend 10% of their revenue on document management, but can’t say for sure where that money is going.
- Misclassified contracts can cause value leakage, with unfulfilled supplier obligations costing a large enterprise roughly 2% of its total spend, a staggering $40 million per year on a $2 billion spend base.
Traditional approaches have failed:
- Rule-based systems break when document layouts change
- Template matching requires constant maintenance
- Manual sorting creates bottlenecks and errors
- Basic OCR solutions can't handle variations in format
- Siloed departmental systems create information barriers
This guide provides a definitive overview of modern AI document classification. We will break down how the technology works, from foundational machine learning for document classification to advanced deep learning techniques. We will explore the critical role of OCR in the classification pipeline, detail practical implementation steps, and show how leading organizations use this technology to achieve significant ROI.
What is document classification? The foundation of automated workflows
Document classification is the process of automatically assigning a document to a predefined category based on its content, layout, and metadata. Its purpose is to enable retrieval, routing, compliance tracking, and downstream automation, forming the critical first step in the document processing workflow.
The core challenge that automated document classification solves is that business documents exist on a spectrum of complexity:
- Structured: These have a fixed layout where data fields are in predictable locations. Think of government forms like a U.S. W-2, a UK P60, or standardized passport applications.
- Semi-structured: This is the majority of business documents. The key data is consistent (e.g., an invoice always has an invoice number), but its location and format vary. Examples include invoices from different vendors, purchase orders, and bills of lading.
- Unstructured: This category covers free-form text, where meaning is derived from the language and context, rather than the layout. Examples include legal contracts, emails, and business reports.
A modern system performs classification across multiple dimensions to make an accurate judgment:
- Text analysis: Analyzing the text using Natural Language Processing (NLP) to understand what the document is about. It identifies key fields and data points and recognizes industry-specific terminology.
- Layout analysis: Mapping spatial relationships between elements. It identifies tables, headers, and sections and recognizes logos and formatting patterns.
- Metadata analysis: Using attributes like creation date, source system, language, or privacy markers. It looks at file source and routing information, as well as security and access requirements.
This multidimensional approach enables a system to make distinctions crucial for business operations, such as distinguishing between an invoice and a purchase order in finance, a lab report and a discharge summary in healthcare, or an NDA and an employment contract in legal. To accomplish this, modern systems rely on a powerful engine of core technologies.
How modern classification works: The complete technology stack
A modern classification system doesn't rely on a single algorithm; it’s powered by an integrated engine that ingests, digitizes, and understands documents before a final decision is ever made. This engine has several critical layers, starting with the foundational technologies that process the raw files.
The foundational layer: OCR for document classification
Before any automated document classification can happen, a document must be converted into a format the system can analyze.
For the millions of scanned PDFs, smartphone pictures, and handwritten notes that businesses run on, Optical Character Recognition (OCR) is the essential first step. It converts a picture of a document into machine-readable text, a foundational technology for any organization looking to digitize its processes.
While older OCR struggled with messy documents, modern, AI-enhanced versions excel. For example, open-source models like Nanonets' DocStrange can natively identify and digitize complex structures like tables, signatures, and mathematical equations, providing rich, structured text for deeper analysis. This advanced capability is crucial for any effective OCR document classification pipeline.
Adding context: The role of NLP
Once the text is digitized, NLP provides the understanding. It enables the system to analyze language for semantic meaning, discerning the intent and context that are crucial for accurate classification.
This is what moves a system from simply matching keywords to truly comprehending a document's purpose. For instance, a purchase order and a sales contract might both contain similar financial terms. Still, an NLP model can analyze the verbs, entities, and overall context to differentiate them correctly. This capability is essential for accurately classifying unstructured documents, such as legal contracts, where meaning is found in the language rather than a predictable layout.
A modern classification system doesn't rely on a single algorithm; it’s powered by an integrated engine that ingests, digitizes, and understands documents before a final decision is ever made. This engine features several critical layers, ranging from foundational components that process raw files to advanced algorithms that provide a deep contextual understanding.
The true breakthrough in modern classification is the combination of core technologies from OCR and NLP with powerful learning algorithms. This is where a system moves from simply digitizing and reading a document to making an intelligent, automated judgment.
Document classification using Machine Learning
The foundation of document classification using machine learning lies in classical algorithms that have been refined over the course of decades. These models are well-suited for text-heavy tasks and are often implemented using robust libraries, such as Python's Scikit-learn. Common models include:
- Naive Bayes: A fast and effective classifier that uses probability to determine the likelihood that a document belongs to a category based on the words it contains.
- Support Vector Machines (SVM): A highly accurate model that works by finding the optimal boundary or "hyperplane" that best separates different document classes.
- Random Forests: An ensemble method that combines multiple decision trees to improve accuracy and prevent overfitting, making it a reliable choice for diverse datasets.
Document classification using Deep Learning
For the highest level of understanding, particularly with complex semi-structured and unstructured documents, state-of-the-art systems use deep learning. Unlike classical models, deep learning can understand the sequence and context of words, leading to more nuanced classification.
The current standard is Multimodal AI, which fuses OCR with NLP in a single, powerful model. Instead of a sequential process, multimodal models analyze a document’s visual layout and its textual content simultaneously. The model recognizes the visual structure of an invoice—the logo placement, the table format—and combines that with its textual understanding to make a confident decision.
For the most complex datasets, advanced models may even use Graph Convolutional Networks (GCNs) to create a "relationship map" of an entire document set. This provides the model with global context, enabling it to understand that an "invoice" from one vendor is related to a "purchase order" from another.
Making advanced models practical at scale
A powerful AI engine must be deployed efficiently to be practical at an enterprise scale. The brute-force approach of applying one massive model to every document is slow and expensive. Modern systems for automated document classification are built differently.
- The lightweight first pass: The intelligent workflow often begins with a lightweight, rapid model that classifies documents based on simple features, such as the filename. Research shows that this initial step can be up to 442 times faster than a full deep-learning analysis, correctly handling clearly named documents with an accuracy of over 96%. Only ambiguous files (e.g., scan_082925.pdf) are routed for deeper, multimodal analysis.
- Intelligent processing for long documents: When long documents like legal contracts require deeper analysis, the system doesn't need to process every single word. Instead, it uses relevance ranking to create a "semantic summary" containing only the most informative sentences. This technique has been proven to reduce inference time by up to 35% with no loss in classification accuracy, making it practical to analyze lengthy reports and agreements at scale.
Training document classification models: Real-world challenges and solutions
Training an effective document classification model is where the promises of AI meet the messy reality of business operations. While vendors often showcase "out-of-the-box" solutions, a successful real-world implementation requires a pragmatic approach to data quality, volume, and ongoing maintenance. The core challenge is that a staggering 77% of organizations report that their data quality is average, poor, or very poor, making it unsuitable for AI without a clear strategy.
Let's break down the real-world challenges of training a model and the modern solutions that make it practical.
a. The cold start challenge: Using machine learning for document classification with little to no data
The most significant hurdle for any organization is the "cold start" problem: how do you train a model when you don't have a massive, pre-labeled dataset? Traditional approaches that demanded thousands of manually labeled documents were impractical for most businesses. Modern platforms solve this with three distinct, practical approaches.
1. Zero-shot learning
What it is: The ability to start classifying documents using only a category name and a clear, plain-English description of what to look for.
How it works: Instead of learning from labeled examples, these models employ techniques such as Confidence-Driven Contrastive Learning to understand the semantic meaning of the category itself. The model matches the content of an incoming document to your description without any initial training documents.
Best for: This is ideal for distinct document categories where a clear description can effectively separate one from another. This principle is the technology behind our Zero-Shot model. You define a new document type not by uploading a large dataset, but by providing a clear description. The AI uses its existing intelligence to start classifying immediately.
2. Few-shot learning
What it is: The ability to train a model with a very small number of samples, typically between 10 and 50 per category.
How it works: The model is architected to generalize effectively from limited examples, making it ideal for quickly adapting to new or specialized document types without needing a large-scale data collection project.
Best for: This is ideal for highly specialized or rare document types where collecting a large dataset is not feasible.
3. Pre-trained models
What it is: Using a model that has already been pre-trained on millions of documents for a common use case (like invoices or receipts) and then fine-tuning it for your specific needs.
How it works: This approach significantly reduces initial training requirements and allows organizations to achieve high accuracy from the start by building on a powerful, pre-existing foundation.
Best for: Common business documents like invoices, receipts, and purchase orders, where a pre-trained model provides an immediate head start.
b. The data quality problem: Good data in, good results out
The quality of your training data has a direct impact on the accuracy of your classification. This is a major point of failure; the AIIM report found that only 23% of organizations have established processes for data quality monitoring and preparation for AI.
Key quality requirements include:
- Resolution: A minimum of 1000x1000 pixel resolution for images and 300 DPI for scanned documents is recommended to ensure text is clear.
- Readability: Text must be readable and free from excessive blur or distortion.
- Annotation consistency: It is critical to follow the same convention when annotating data. For example, if you annotate the date and time in a receipt under the label date, you must follow the same practice in all receipts.
- Completeness: Do not partially annotate documents. If an image has 10 fields to be labeled, ensure all 10 are annotated.
c. The stagnation problem: Ensuring continuous improvement
Classification models are not static; they are designed to improve over time by learning from their environment.
1. Instant Learning:
What it is: The model is architected to learn from every single human correction in real-time. When a user in the loop approves a corrected document or reclassifies a file, that feedback is immediately incorporated into the model's logic.
Benefit: This eliminates the need for manual, periodic retraining projects and ensures the model automatically adapts to new document variations as they appear.
2. Performance monitoring:
AI Confidence Score: Modern platforms provide a dynamic "AI Confidence" score for each prediction. This metric quantifies the model's ability to process a file without human intervention and is crucial for setting automation thresholds. It is a dynamic measure of how capable the AI model is of processing your files without human intervention.
Business and technical KPIs: Continuously track technical metrics like accuracy and straight-through-processing (STP) rates, alongside business metrics like processing time and error rates, to identify areas for improvement and flag systematic errors.
With a clear path to training an accurate and continuously improving model, the conversation shifts from technical feasibility to tangible business outcomes.
Automated document classification in action: Use cases and proven ROI
The benefits of moving from manual sorting to intelligent classification are not theoretical. They are measured in saved hours, direct cost reductions, and mitigated operational risks. While the business case is unique for every company, a clear benchmark for success has been established in the industry.
| Industry | Common Documents | Automated Workflow | Business Value |
|---|---|---|---|
| Finance & Accounting | Invoices, Purchase Orders, Receipts, Tax Forms, Bank Statements | Classify incoming documents to trigger 3-way matching, route high-value invoices for special approval, and export validated data to an ERP like SAP or NetSuite. | Faster AP/AR cycles, reduced reconciliation errors, and proactive prevention of duplicate payments and fraud. |
| Healthcare | Patient Records, Lab Reports, Insurance Claims (e.g., HCFA-1500 forms), Vendor Compliance Files | Sort patient files for EHR systems, classify vendor documents for compliance checks, and automatically route claims to the correct adjudication team. | Faster record retrieval, improved interoperability, robust HIPAA compliance, and a significant reduction in vendor onboarding time. |
| Legal & Compliance | Contracts, NDAs, Litigation Filings, Discovery Documents, Compliance Reports | Triage new contracts by type (e.g., NDA vs. MSA), flag specific clauses for expert review, and automatically monitor for compliance deviations against transactional data. | Faster due diligence, a significant reduction in manual legal review hours, and proactive risk mitigation before contracts are executed. |
| Logistics & Supply Chain | Bills of Lading, Purchase Orders, Delivery Notes, Customs Forms, Shipping Receipts | Automatically split multi-document shipping packets, classify each document, and route them to customs, warehouse, and finance systems simultaneously. | Faster customs clearance, fewer shipping delays, improved supply chain visibility, and more accurate inventory management. |
| Human Resources | Resumes, Employee Contracts, Onboarding Forms (e.g., I-9s, P45s), Performance Reviews, Expense Reports | Classify applicant resumes to route them to the correct hiring manager, and automatically organize all onboarding documents into digital employee files. | Faster hiring cycles, streamlined employee onboarding, easier compliance with labor laws, and more efficient internal audits. |
The benchmark: What separates the best from the rest
According to a comprehensive 2024 study by Ardent Partners, the performance gap between an average Accounts Payable department and a "Best-in-Class" one is defined almost entirely by the level of automation. The study found that Best-in-Class AP teams achieve invoice processing times that are 82% faster and at a 78% lower cost than all other groups.
Achieving this level of performance is not a mystery; it is the direct result of applying the technologies discussed in this guide. Let's examine how specific businesses have achieved this.
| Metric | Manual Processing | Automated Processing |
| Time per document | 5-10 minutes | < 30 seconds |
| Cost per document | ~$9.40 (Industry Avg.) | ~$2.78 (Best-in-Class) |
| Error rate | 5-10% (manual entry) | < 1% (with validation) |
Example 1: Taming complexity in manufacturing
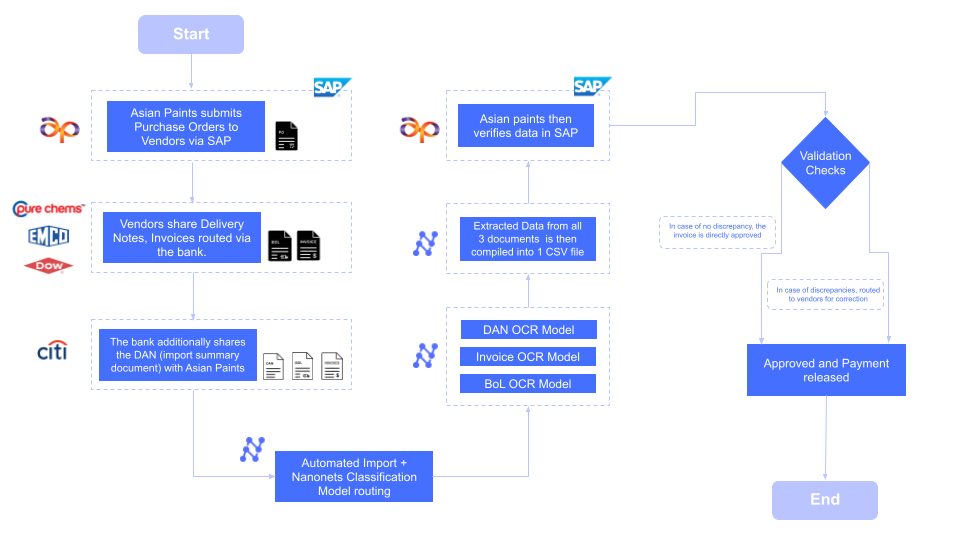
Asian Paints, a global manufacturer, faced a complex challenge: processing documents from 22,000 vendors on a daily basis. Each transaction required multiple document types, purchase orders, delivery notes, and import summaries, all flowing into a single inbox.
Their implementation approach:
- Automated classification to identify document types
- Direct routing of invoices to SAP
- Separate workflow for delivery notes and POs
- Automated matching of related documents
Results:
- Processing time: 5 minutes → 30 seconds per document
- Time saved: 192 person-hours monthly
- Scope: Successfully handling 22,000+ vendor documents daily
- Error reduction: Automated duplicate detection caught $47,000 in vendor overcharges
Example 2: Ensuring compliance and scale in healthcare
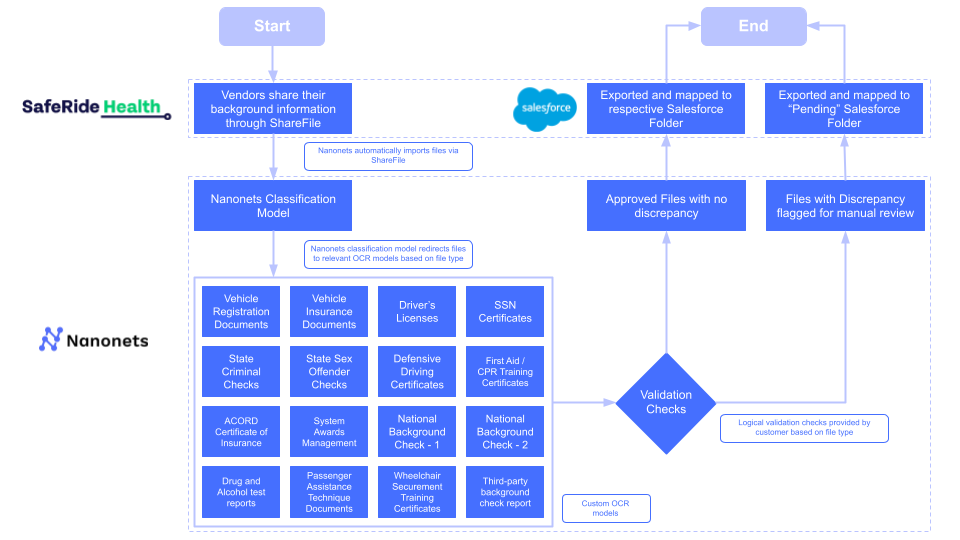
SafeRide Health needed to verify and classify 16 different document types for each transportation vendor, from vehicle registrations to driver certifications. Manual processing created bottlenecks in vendor onboarding.
Implementation strategy:
- Classification model trained for each document type
- Automatic routing to validation workflows
- Integration with Salesforce for vendor management
- Real-time status tracking
Results:
- Manual workload reduced by 80%
- Team efficiency increased by 500%
- Automated validation of compliance documents
- Faster vendor onboarding process
Example 3: Scaling AP operations
Augeo, an accounting firm processing 3,000 vendor invoices monthly, needed to streamline their document handling within Salesforce. Their team spent 4 hours daily on manual data entry.
Solution architecture:
- Automated document classification
- Direct integration with Accounting Seed
- Automated data extraction and upload
- Exception handling workflow
Results:
- Processing time: 4 hours → 30 minutes daily
- Capacity: Successfully handling 3,000+ monthly invoices
- Improved service delivery to existing clients
- Added capacity for new clients without headcount increase
Implementation plan: Your path from manual sorting to automated workflows
This is not a six-month IT overhaul. For a focused scope, you can go from a chaotic inbox to your first automated classification workflow in just a week or two. This blueprint is designed to deliver a tangible win quickly, building momentum for broader adoption.
Step 1: Define & ingest
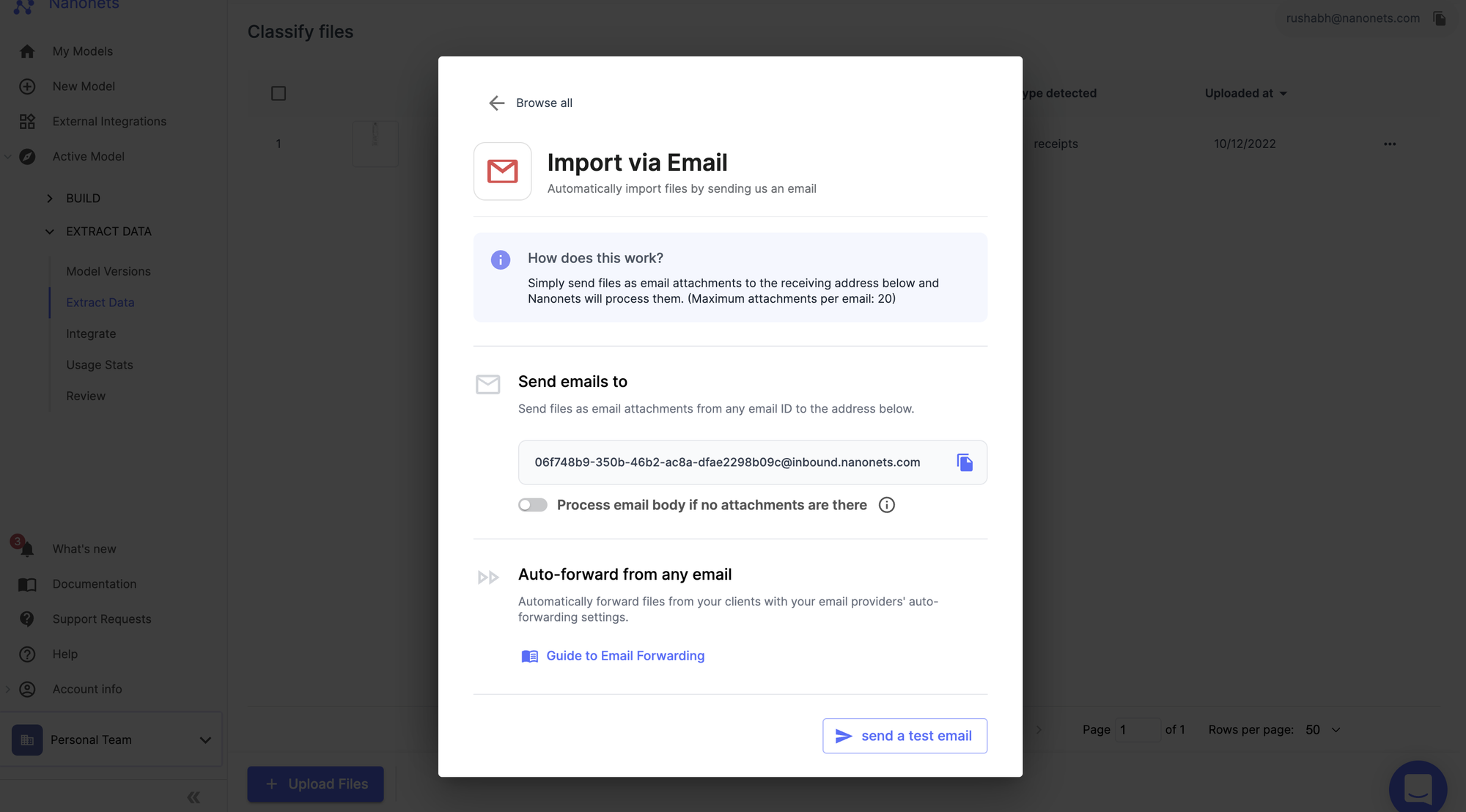
The goal is to establish the scope of your initial project and set up the data pipeline.
- Identify the target: Choose 2-3 of your highest-volume, most problematic document types. A common starting point for finance teams is separating Invoices, Purchase Orders, and Credit Notes.
- Gather samples: Collect at least 10-15 diverse examples of each document type. This is a critical step; using only clean, simple examples is a common mistake that leads to poor real-world performance.
- Set up your model: Within the Nanonets platform, create a new Document Classification Model. For each document type, create a corresponding label (e.g., Invoice-EU, Purchase-Order).
- Connect your source: In the Workflow tab, set up an automated import channel. Connect your ap@company.com inbox or a designated cloud folder (OneDrive, Google Drive, etc.). Nanonets checks for new files every five minutes.
Step 2: Train and test
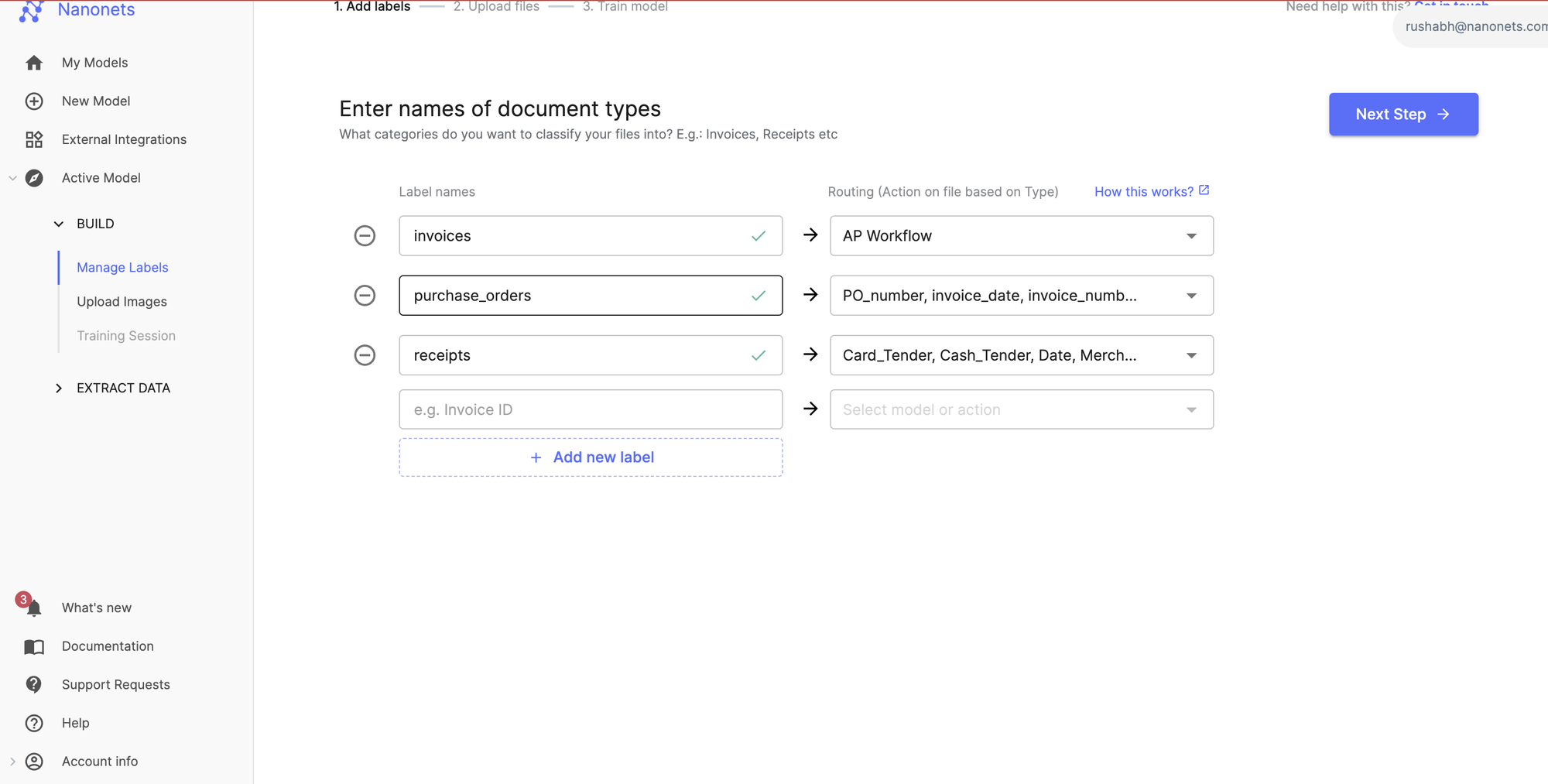
Next, focus on training the initial AI model and establishing a performance baseline.
- Train the model: Upload your sample documents to their corresponding labels.
- Process a validation set: Feed a separate batch of 20-30 mixed documents (not used in training) through the system to get your first look at the model's performance and a baseline accuracy score.
- Analyze Confidence Scores: For each document, the model will return a classification and a confidence score (e.g., 97%). Reviewing these scores is crucial for setting your initial threshold for straight-through processing.
Step 3: Configure rules & human-in-the-loop
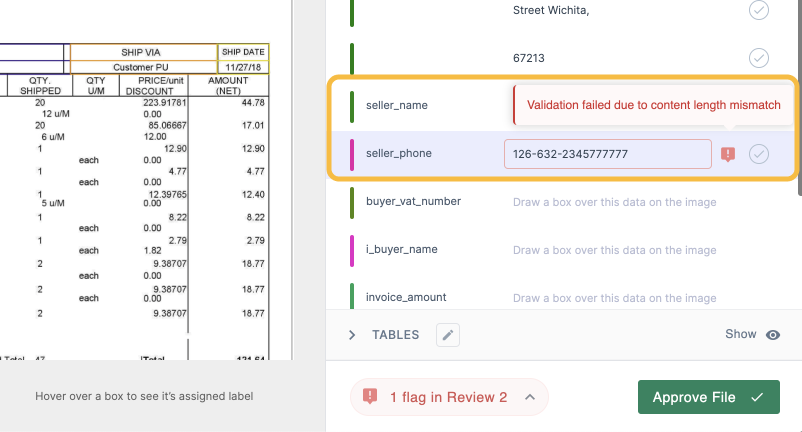
With a baseline model working, next, you need to embed your specific business rules into the workflow.
- Define routing logic: Map out where each classified document should go. In the Nanonets Workflow builder, this is a visual, drag-and-drop process to connect your classification model to other modules, such as a specialized data extraction model for invoices or an approval queue.
- Set up the Human-in-the-Loop (HITL) Workflow: No model is perfect initially. Configure the system to route any documents that fall below your confidence threshold (e.g., <85% confidence) to a specific user for a quick, 15-second review. This builds trust and provides a vital feedback loop for the AI.
Step 4: Connecting to your systems
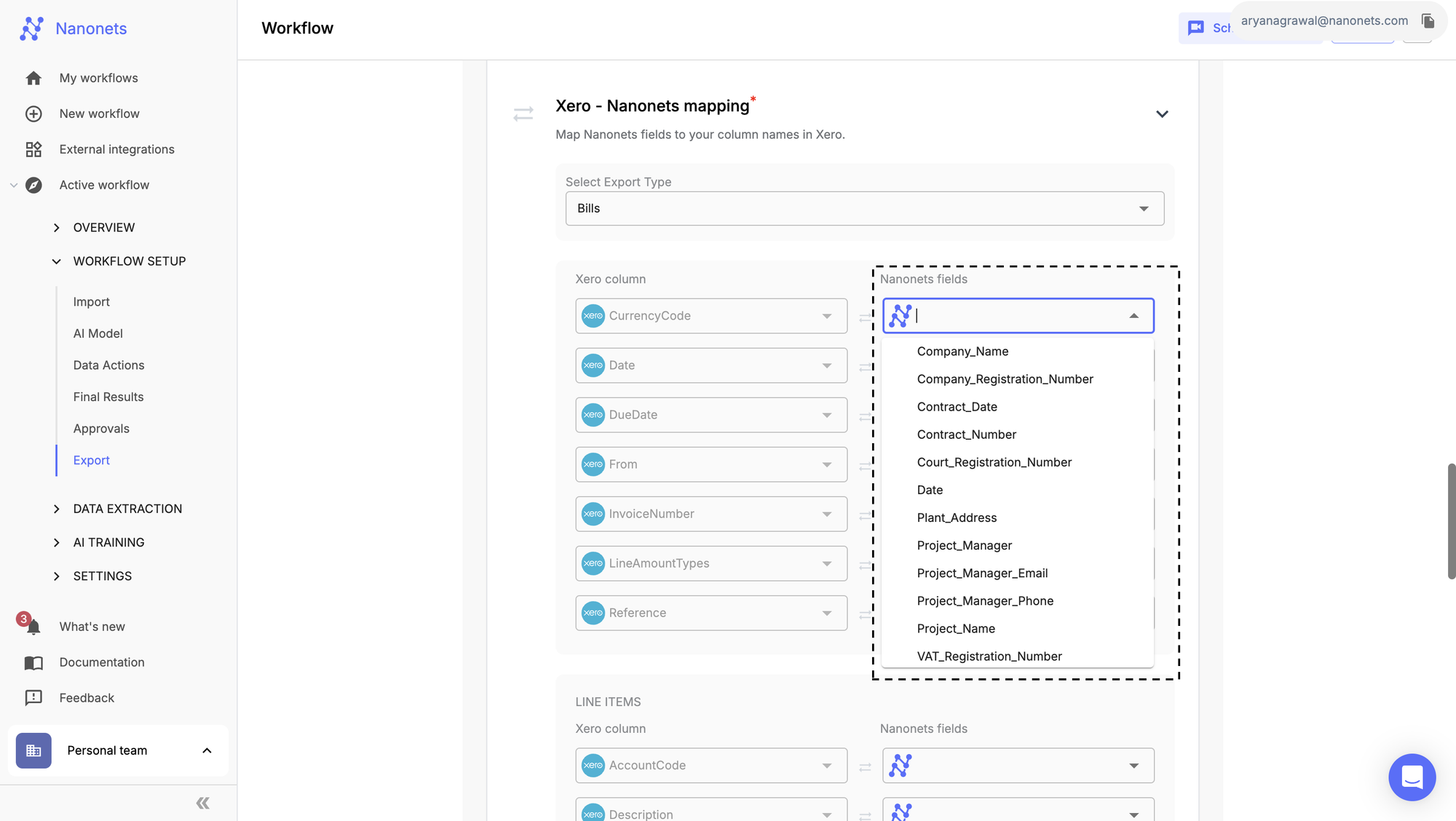
The final step is about connecting the automated workflow to your existing business systems.
- Connect your outputs: Configure the export step of your workflow. This could involve a direct API integration with your ERP (such as SAP or NetSuite), accounting software (like QuickBooks or Xero), or a shared database.
- Go live: Activate the workflow. All incoming documents for your chosen process will now be automatically classified, routed, and processed, with human oversight only for the exceptions.
- Common mistakes to avoid:
- Training with non-representative data: Using only clean examples instead of the messy, real-world documents your team actually handles.
- Setting automation thresholds too high: Demanding 99% confidence from day one will route everything for manual review. Start at a lower value (e.g., 85%) and increase it as the model learns.
- Ignoring the user experience: Ensure the software vendor you select has an HITL interface that is fast and intuitive; otherwise, your team will see it as another bottleneck.
Future-proofing your operations: The strategic outlook
Adopting document classification is more than an efficiency upgrade; it’s a strategic imperative that prepares your organization for the future of work, compliance, and automation.
The AI-augmented workforce: rise of the AI agents
The PwC 2025 AI Business Predictions report states that your knowledge workforce could effectively double, not through hiring, but through the integration of AI agents—digital workers that can autonomously perform complex, multi-step tasks.
Document classification is the foundational skill for these agents. An AI agent must first identify the type of a document before it can take the next step, whether that involves drafting a response, updating a CRM, or initiating a payment workflow. Organizations that master classification today are building the essential infrastructure for the AI-augmented workforce of tomorrow.
Wrapping up: Classification is the gateway to full automation
Document classification is the first step to end-to-end document automation. Once a document is accurately classified, a chain of automated actions can be triggered. An "invoice" can be routed for extraction and payment; a "contract" can be sent for legal review and signature; a "customer complaint" can be routed to the appropriate support tier.
This is the core principle behind a modern workflow automation platform. Nanonets enables you to go way beyond simple sorting; you get complete, end-to-end automation your business actually needs — from email import to ERP export.
FAQs
Can the system handle documents in multiple languages simultaneously?
Document classification systems support multiple languages and scripts without requiring separate models. The technology combines: Language-agnostic visual analysis for layout and structure, Multilingual OCR capabilities for text extraction, and Cross-language semantic understanding.
This means organizations can process documents in different languages through the same workflow, maintaining consistent accuracy across languages. The system automatically detects the document language and applies appropriate processing rules.
How does the system maintain data privacy and security during classification?
Document classification platforms implement multiple security layers:
End-to-end encryption for all documents in transit and at rest
Role-based access control for document viewing and processing
Audit trails tracking all system interactions and document handling
Configurable data retention policies
Compliance with major standards (SOC 2, GDPR, HIPAA)
Organizations can also deploy private cloud or on-premises solutions for enhanced security requirements.
How does the system adapt to new document types or changes in existing formats?
Modern classification systems use adaptive learning to handle changes:
- Continuous learning from user corrections and feedback
- Automatic adaptation to minor format changes
- Easy addition of new document types without full retraining
- Performance monitoring to detect accuracy changes
- Graceful handling of document variations and updates
What level of technical expertise is required to maintain the system after implementation
Day-to-day system maintenance requires minimal technical expertise:
- Visual interface for workflow adjustments
- No-code configuration for most common changes
- Built-in monitoring and alerting
- Automated model updates and improvements
- Standard integrations managed through UI
Technical teams may be needed for:
- Custom integration development
- Advanced workflow modifications
- Performance optimization
- Security configuration updates
- Custom feature development
What is OCR document classification?
OCR document classification is a two-stage automated process. First, Optical Character Recognition technology scans a document image (like a PDF or JPG) and converts it into machine-readable text. Then, a machine learning model analyzes this extracted text and the document's layout to assign it to a predefined category, such as 'invoice' or 'contract'. This allows businesses to automatically sort and route both digital and paper-based documents in a single workflow.
What is the role of deep learning in document classification?
Deep learning is critical for modern document classification because it allows models to understand complex patterns in content and layout without being manually programmed. Deep learning models, particularly multimodal and graph-based architectures, can analyze text, images, and document structure simultaneously. This enables them to achieve over 90% accuracy on semi-structured and unstructured documents like invoices and legal agreements, where older machine learning methods would fail.
What is the difference between supervised and unsupervised classification?
The primary difference between supervised and unsupervised classification lies in how the AI model learns and whether it uses pre-labeled data.
Supervised Classification requires a human to provide a set of labeled training documents. In this method, you explicitly teach the model what each category looks like by feeding it examples (e.g., 50 documents labeled "Invoice," 50 labeled "Contract"). The model learns the patterns from these labeled examples to predict the category for new, unseen documents. This is the most common approach for tasks where the categories are well-defined.
Unsupervised Classification (also known as document clustering) is used when you do not have labeled data. The AI model analyzes the documents and automatically groups them into "clusters" based on their inherent similarities in content and context. It discovers the underlying patterns on its own without predefined categories, which is useful for exploring a new dataset to see what natural groupings emerge.
A third approach, Semi-Supervised Classification, offers a practical middle ground, using a small amount of labeled data to help guide the classification of a much larger pool of unlabeled documents.
What is the difference between document classification and categorization?
While often used interchangeably, there is a subtle but essential distinction between document classification and categorization, primarily concerning the level of structure and purpose.
Document Categorization is a broader, more flexible process of grouping documents based on diverse criteria, such as topic, purpose, or other characteristics. It can be done manually or automatically and is primarily for general organization and retrieval, like sorting files into folders named "Marketing" or "Finance".
Document Classification is a more systematic and often automated process of assigning documents to specific, predefined classes based on a rigid set of rules or a trained model. This is typically done for a specific downstream purpose, such as routing, compliance, or security. For example, a system would classify a document as "Confidential-Legal" to automatically restrict access, rather than just categorize it.
In short, categorization is about grouping for organization, while classification is about assigning for a specific, often automated, business purpose.