

Staring at a pile of handwritten documents, wondering how to turn them into something searchable or editable? We’ve all been there - trying to make sense of scribbled meeting notes or digitizing old documents into something usable.
For businesses in industries like healthcare, legal, or finance, converting handwriting to text isn’t just a task — it’s a necessity. Many people deal with handwritten documents like patient notes, receipts, and contracts on a daily basis, and digitizing them is essential.
But how exactly are you supposed to do that? Manually copy pasting? Sure, if you’ve got endless time and patience. AI tools? They’re great… until they misread “12” as “IZ.”
Despite advancements in OCR and AI-powered software, converting handwriting to text with 100% accuracy remains a challenge. I'll explore the tools and methods that can help you tackle it:
| Method | Summary | Pros | Cons |
|---|---|---|---|
| Manual Transcription | Human operators transcribe handwritten documents into digital formats. | - Human understanding of context - Error correction - Adaptability to complex formats |
- Time-intensive - Expensive - Susceptible to human error |
| Online Converters | Uses OCR to convert handwriting to text; suitable for small projects. | - Speed - Accessibility (often free or low cost) |
- Lower accuracy with complex handwriting - Security concerns - Limited customization |
| Python Libraries | Custom OCR solutions using libraries like Tesseract. | - Customizability - Integration flexibility - Cost-effective for large volumes |
- Requires technical expertise - Lower accuracy with complex handwriting - Processing time can be significant |
| AI-based Intelligent Document Processing (IDP) | AI-powered platforms for high-accuracy handwriting interpretation. | - High accuracy with complex handwriting - Contextual understanding - Adaptability across document types - Scalability and speed - Custom model training |
- Costly for small-scale use - Requires setup and training for custom models |
Challenges in handwriting-to-text conversion
I’ve had my fair share of struggles with converting handwritten notes into digital text.
Doing it manually takes a lot of time, and I end up making a lot of mistakes. Even after trying some OCR tools, I had to verify, correct and make many changes at the end.
The real challenge, I think, lies in the sheer variability of handwriting styles and contextual understanding. Even humans often find some handwriting illegible. How are machines expected to interpret it accurately? Smudges, poor penmanship, and inconsistent handwriting complicate the process.
In this section, we’ll explore the specific challenges of handwriting to text conversion, along with practical use cases that highlight these problems:
1. Variability in handwriting styles and contextual understanding
Handwriting is as unique as a fingerprint. Slants, letter shapes, spacing, and pressure vary with each individual, and AI tools often struggle to generalize across styles.
It often lacks clarity, especially in context-heavy documents like medical prescriptions or notes, where abbreviations and jargon are common.
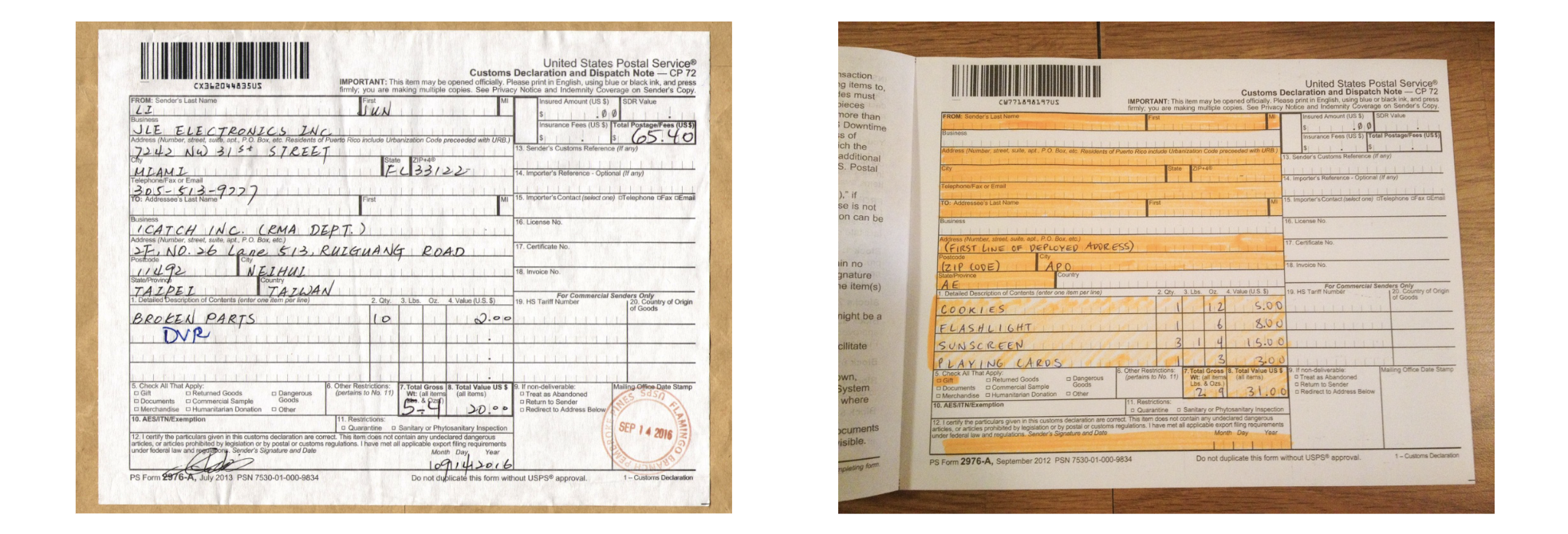
In the legal industry, where handwritten case notes, client agreements, and testimonies are common, different handwriting styles can make automated digitisation challenging, leading to significant errors.
Healthcare providers may use medical symbols that are hard to interpret. Misreading a medical prescription can lead to serious errors, making high-accuracy recognition essential but difficult due to the need for context-aware systems.
{kind=link}
2. Noise from scanning
Ever scanned a crumpled receipt or a document with smudged ink? I’ve dealt with plenty of such cases, and it’s a nightmare. Poor lighting, paper quality, or defects like folds and tears only add to the noise, significantly reducing handwritten text recognition accuracy and adding to the challenge of handwriting to text conversion.
In insurance claims processing, where agents often scan accident reports or damage assessments, the presence of smudges, marks, or tears in handwritten documents can hinder accurate text extraction, delaying the claim processing time.

{kind=link}
3. Lack of training data for specific languages and scripts
Not all writing systems are created equal. OCR models, fuelling modern-day Intelligent Document Processing (IDP) tools, need extensive training data to accurately interpret various scripts, alphabets, or writing systems.
However, handwriting datasets for lesser-used languages or scripts may not be readily available. This causes issues when it comes to accurate conversion of lesser-used languages and scripts.
In global logistics, multi-lingual delivery addresses or customs documentation handwritten in non-Latin alphabets (e.g., Arabic, Hindi) present difficulties in automation. The lack of representative training data for some of these languages compounds the problem.
4. Recognition of structured data (forms, tables)
Oh, documents with fixed tables filled with illegible handwriting are the worst! I've tried OCR on handwritten receipts from my local grocery stores.
Converting handwritten forms, or tables requires systems to understand not just the text, but also the layout and structure.
In finance, digitising filled-in tax forms, loan applications or other customer forms that contain a mix of handwritten notes and printed fields requires layout-aware recognition. Systems must understand the distinction between different sections, fields, and columns to avoid misinterpretation.

5. Handling Cursive and Connected Script
Cursive writing is a whole different beast. Makes me wonder if everyone should take compulsory handwriting classes in school.
Cursive handwriting, where letters are often connected, presents unique problems compared to block writing. Systems must differentiate between connected letters and actual spaces, leading to higher error rates.
Doctors often use cursive or semi-cursive handwriting when writing patient notes, prescriptions, or diagnoses in medical records. The flowing script, combined with abbreviations, makes it difficult for handwriting recognition systems to correctly segment individual characters and words.
It’s no surprise that cursive is one of the hardest challenges for handwriting recognition systems.
The need to quickly digitise handwritten records for integration into electronic health systems (EHRs) adds pressure for highly accurate transcription. Poor recognition of cursive script in medical records can delay care, increase administrative workload, and even lead to legal liabilities.

From my experience, knowing these hurdles helps you choose the right tools and set realistic expectations.
Now that we understand the specific set of challenges that affect the conversion process as well as the potential impact, let's look at a few methods to digitise handwritten text that you can choose from.
Methods for converting handwriting to text
In the following section, we will look at a few methods of converting handwritten text into digital text. While manual transcription is one option, it requires significant time and effort. On the other hand, online converters are faster but may struggle with low-quality handwriting, specific formatting as well as pose security concerns. Python libraries like Tesseract OCR can provide automation but often need substantial preprocessing and post-processing to work effectively with handwritten text, not to mention that they require coding proficiency as well.
More advanced solutions involve AI-based Intelligent Document Processing (IDP) systems, which use machine learning models to improve accuracy over time. These tools, including Nanonets, are trained to recognise different handwriting styles and formats, offering businesses a more scalable and reliable method for text extraction. So let's dive in.
1. Using manual transcription for converting handwriting to text
The old-fashioned way: sit down, read the handwriting, and type it out.
Manual transcription involves human operators reading handwritten documents and typing them into digital formats. While time-consuming, it ensures decent accuracy, especially with challenging handwriting or specialized content, given limited volumes. Manual transcription is performed by trained individuals who carefully read and interpret handwritten documents, converting them into digital text.
This method is especially accurate in industries where content complexity and context play a crucial role, such as healthcare, where doctors’ notes or prescriptions may involve specialised medical terms, or legal, where historical documents like contracts and court records have intricate language and formatting.
1. Human Understanding of Context: Transcribers can accurately interpret abbreviations, industry jargon, and contextual meaning that automated systems might miss. For example, legal transcribers can correctly interpret shorthand used in contracts.
2. Error Correction: Humans can detect and correct errors that arise from poor handwriting or unclear symbols, ensuring higher quality in documents like medical records, where minor mistakes can have serious consequences or lead to legal liability.
3. Adaptability to Complex Formats: Transcribers can easily handle complex layouts, diagrams, or nested tables present in legal or research documents, which are difficult for automated systems to process correctly.
1. Time-intensive: Manually transcribing a large volume of documents takes significantly longer compared to automated methods, delaying processes where speed is crucial.
2. Expensive: Manual labor is expensive, especially for industries that require specialised knowledge (e.g., medical or legal transcribers), increasing operational costs for large-scale or recurring projects.
3. Human Error: Although manual transcription is generally accurate, transcribers are still susceptible to mistakes due to fatigue or oversight, especially when dealing with large volumes of handwritten documents over long periods.
My take: I used this for my personal notes during college, and while it worked, I wouldn’t recommend it unless you’re dealing with minimal text or have no other options.
2. Using online converters for converting handwriting to text
Online converters use OCR (Optical Character Recognition) technology to automatically extract text from images or scanned handwritten documents. These tools may be useful for a quick one-off conversion or small projects such as digitising class notes or minutes of meeting, but cannot be employed across industries like banking or healthcare owing to the nature of data involved.
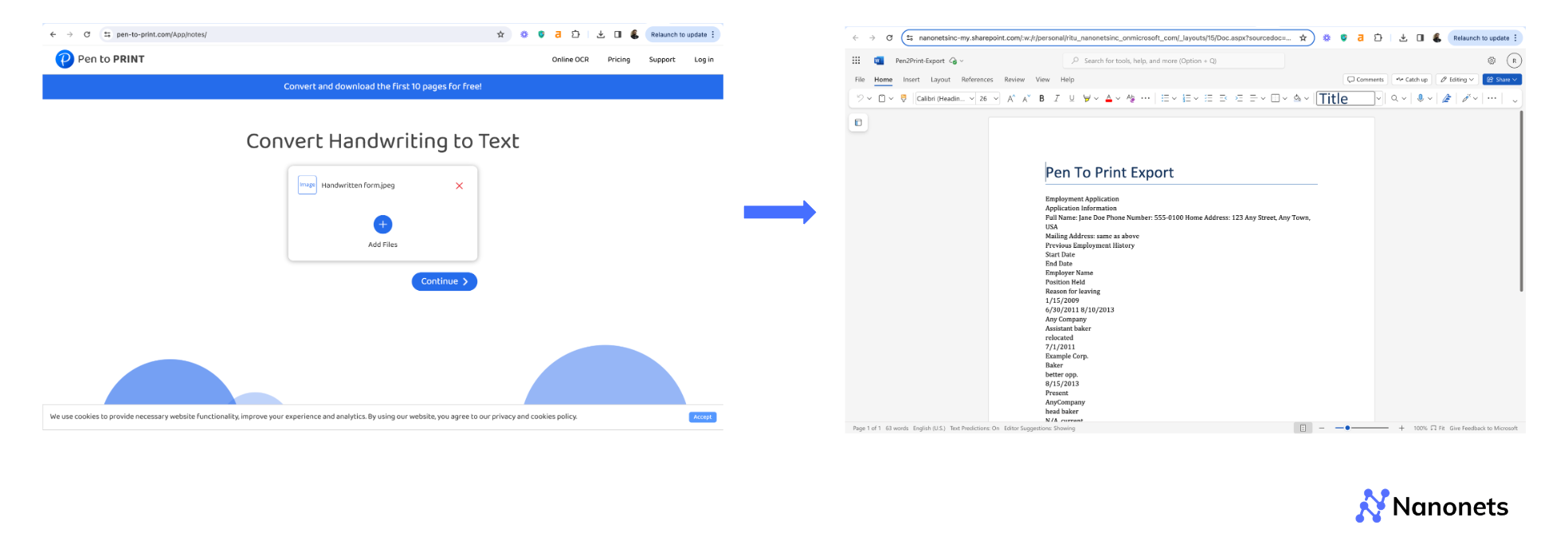
There is another added challenge of losing any kind of formatting completely, as evident from the image below. This makes it unsuitable for converting specialised, context-heavy documents, like, handwritten forms, purchase orders, prescriptions, etc.
Here is a quick general outline of how to go about converting handwritten documents into text:
Step 1: Go to the converter's website. (In this case, we tried pen-to-print that offers limited free usage).
Step 2: Upload your file/image and click on "Continue".
Step 3: Select your output format and then click, "Download".
1. Speed: Online converters process documents quickly, making them ideal for industries with high document volumes, such as banking or administrative tasks.
2. Accessibility: Many online converters are easy to use, often available for free or at low cost, allowing businesses or individuals to quickly access OCR technology without the need for specialized software.
1. Lower Accuracy with Complex Handwriting: Handwritten documents with cursive, sloppy, or stylised writing often lead to recognition errors, especially in industries like healthcare, where doctor’s notes are notoriously hard to decipher.
2. Security Concerns: Sensitive documents, such as medical records or legal contracts, may not be safe when uploaded to third-party online converters, posing risks related to data breaches or confidentiality.
3. Limited Customisation: Unlike manual transcription or custom-trained OCR models, online converters generally cannot be tailored to handle specialized formats, terminology, or complex layouts found in legal or research documents.
Best for: Quick, non-critical tasks like digitizing grocery lists or to-do notes.
3. Using Python libraries for converting handwriting to text
Python libraries such as Tesseract, EasyOCR, and TensorFlow enable developers to build custom solutions for extracting text from handwritten documents. In this section, we will take a look at a step-by-step process to leverage 'pytesseract' for converting handwritten text to digital text.
This method could potentially find multiple applications, such as the finance industry, where businesses can develop in-house systems to extract data from invoices, receipts or purchase orders. It does offer unique advantages but also comes with its own challenges.
Step 1: Install Required Libraries
Install the necessary libraries for image processing and OCR.
pip install pytesseract opencv-python pillowYou would also need to install Tesseract on your system.
Step 2: Load the Image
Before getting started, we would need to load the image of the handwritten document using Pillow.
from PIL import Image
# Load the image
image = Image.open('handwritten_sample.jpg')
image.show() # Optional: Display the imageStep 3: Pre-process the Image
Handwritten text may require some pre-processing to improve OCR results. Basically, pre-processing an image can:
- Convert the image to grayscale.
- Apply binarization to create a high-contrast black-and-white image.
- Optionally remove noise using a median filter.
import cv2
import numpy as np
def preprocess_image(image_path):
# Load image in grayscale
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# Apply thresholding to binarize the image (black & white)
_, img_bin = cv2.threshold(img, 128, 255, cv2.THRESH_BINARY_INV)
# Optionally remove noise and smooth the image
img_noise_removal = cv2.medianBlur(img_bin, 3)
# Save pre-processed image (for debugging)
cv2.imwrite("preprocessed_image.jpg", img_noise_removal)
return img_noise_removal
preprocessed_img = preprocess_image('handwritten_sample.jpg')Step 4: Use Tesseract to Extract Text
Now that the image is pre-processed, you can use Tesseract via the 'pytesseract' library to extract text. The processed image is fed into Tesseract for OCR.
The config='--psm 6' option specifies that the input image contains a block of text. This would need to be adjusted based on the content.
import pytesseract
def extract_text_from_image(image):
# Perform OCR using Tesseract
text = pytesseract.image_to_string(image, config='--psm 6') # PSM 6 is suitable for single block of text
return textUnified Code:
The main function integrates the image preprocessing and OCR steps. Replace 'handwritten_sample.jpg' with the path to your handwritten document.
There are additional libraries, such as Keras or Pytorch that can be used for developing specialised deep learning models for cursive handwritten documents.
1. Customisability: Python libraries allow developers to fine-tune models for specific handwriting styles, which is particularly useful in domains like healthcare or legal, where documents have specialized terminology or inconsistent formatting.
2. Integration Flexibility: These libraries can be seamlessly integrated into larger systems, allowing industries like finance or insurance to embed OCR directly into their workflows (e.g., automatic processing of claims or receipts).
3. Cost-effective: Once set up, Python-based solutions can be more affordable compared to paid online converters, especially for companies processing large volumes of documents regularly.
1. Technical Expertise Required: Using libraries like Tesseract or TensorFlow requires programming skills and expertise in machine learning, making it harder for non-technical users or small businesses without dedicated IT resources.
2. Lower Accuracy with Complex Handwriting: Although custom models can be trained for specific handwriting styles, the accuracy for messy or cursive writing may still fall short compared to manual transcription, particularly in critical fields like healthcare.
3. Processing Time: Building and training models can take significant time and computing power, especially for large-scale projects such as digitizing historical archives in the research sector.
My experience: I’ve used Tesseract for a small project, and while it worked well with printed text, the results for handwriting were hit-or-miss without significant tweaking.
4. Using AI-based IDPs for converting handwriting to text
AI-based Intelligent Document Processing (IDP) platforms use advanced machine learning models and natural language processing (NLP) to intelligently read, understand, and extract text from handwritten documents.
Unlike traditional OCR, which focuses solely on recognising text characters, AI-based IDP can analyse the context, layout, and structure of documents, making it ideal for industries with high document complexity.
Nanonets can take this a step further by deploying our revolutionary zero-training custom models specifically for handwriting, which can accurately process documents even with inconsistent handwriting styles or complex formatting (example image below).
Let's take a look at how to convert handwritten documents into text using Nanonets:
Step 1: Go to app.nanonets.com and sign in.
Step 2: Click on "New Workflow" > "Zero-training extractor".
Step 3: If it is a key-value pair you are extracting, enter the label name in "Fields", example, Full Name, Home Address, etc.
If it is a table column header, enter it in "Table Header" section.
Step 4: Once set up, click Continue and upload your file. After a few seconds, the extracted data will be ready for review.
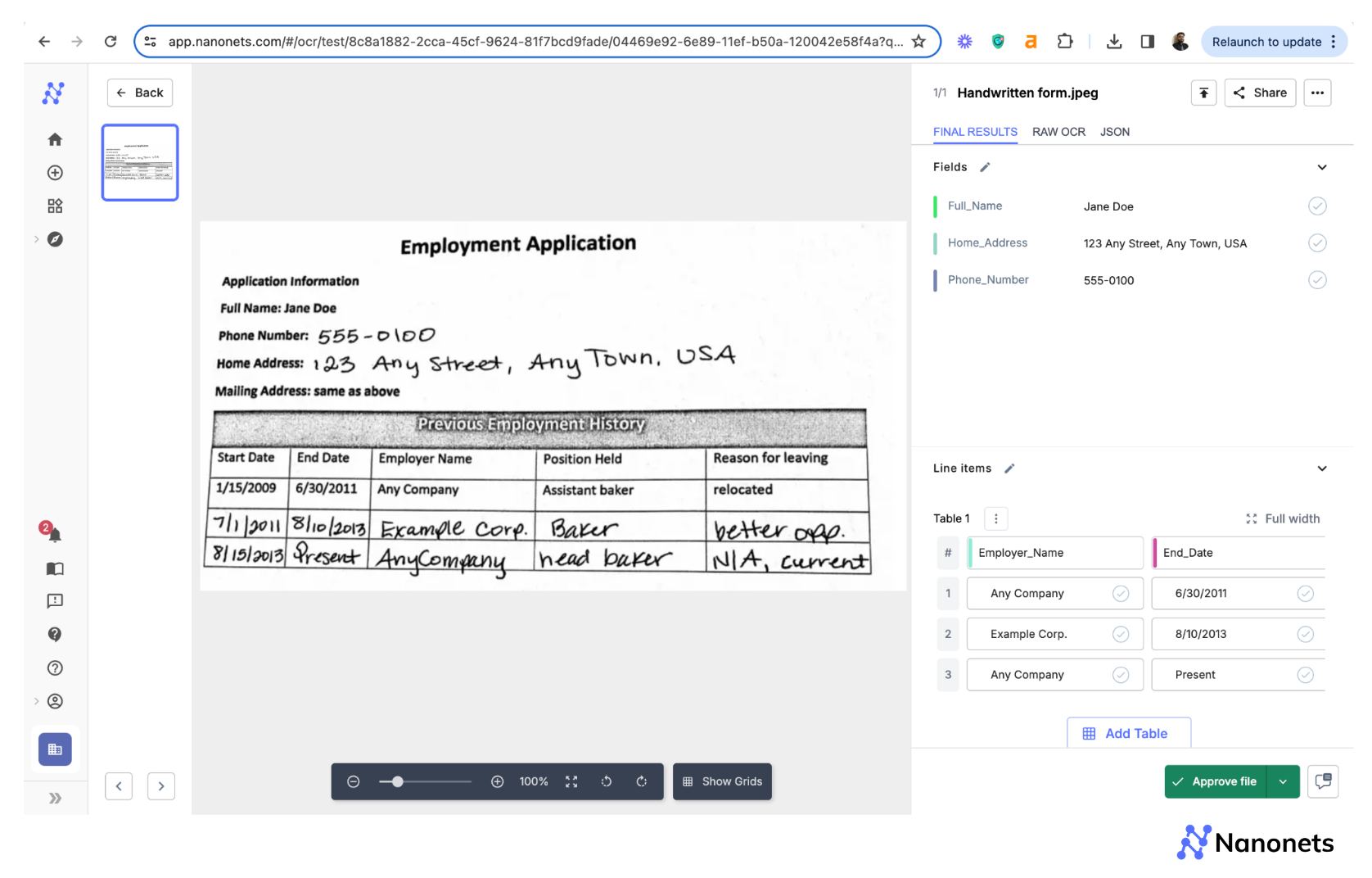
1. High Accuracy with Complex Handwriting: AI-based IDPs excel at reading and interpreting cursive, stylized, or poorly written handwriting.
2. Contextual Understanding: Unlike traditional OCR, AI models understand the context behind the text, allowing them to extract information more accurately. In finance, for instance, Nanonets can easily capture key fields from invoices (e.g., vendor names, amounts, and dates) even when handwriting is inconsistent.
3. Adaptability Across Document Types: AI-based platforms like Nanonets can handle a wide range of documents across industries. For example, in healthcare, Nanonets can extract patient data from medical forms, prescriptions, and handwritten doctor’s notes with a high degree of precision.
4. Scalability and Speed: AI-based IDPs can process large batches of documents efficiently. In insurance, companies can automate claims processing by extracting handwritten information from forms without sacrificing accuracy.
5. Custom Model Training: Nanonets allow businesses to train custom models based on specific handwriting styles or industry-specific documents, providing unmatched flexibility.
Why it works: I’ve personally used Nanonets to process handwritten customer forms, and the accuracy was impressive—even for messy handwriting. It also handled layouts like tables and forms seamlessly, saving hours of manual effort.
Summary
The best method for you depends on the volume and complexity of the handwritten text, as well as your technical expertise. If you’re working on a one-off task, online converters might suffice. For more complex needs, especially at scale, AI-based IDP tools are the way to go.
In summary, while we agree that AI-based IDPs like Nanonets offer the perfect blend of accuracy, scalability, and customisability, conversion of handwritten documents into digital text is in general tricky business.
In researching about this article, we tried out a number of solutions, none of which offered even close to 100% accuracy. The solution with the highest level of accuracy was AI-based IDPs, more specifically, Nanonets, which offered accuracy in the range of 80-85%. Accurate recognition of cursive handwriting or documents written in different handwritings is nearly impossible unless you utilise real-time conversion tools.
This makes Nanonets, an excellent choice for industries that require highly accurate and context-aware handwriting recognition at scale.